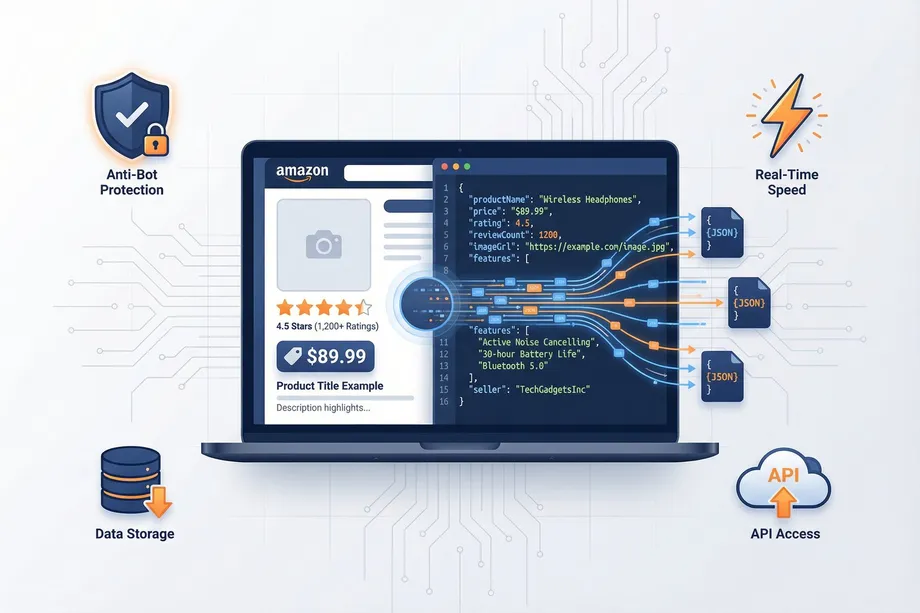
Amazon represents one of the largest data oceans in the e-commerce world. For developers and businesses seeking to perform price monitoring, competitor analysis, or market research, this data is like a gold mine. But how can you programmatically access this valuable information? The answer lies in Python and web scraping techniques.
In this comprehensive guide, we'll explore two fundamental approaches to extracting product data from Amazon: the traditional (and challenging) path and the modern, efficient API solution. Through step-by-step code examples, we'll reveal the advantages and disadvantages of both approaches.
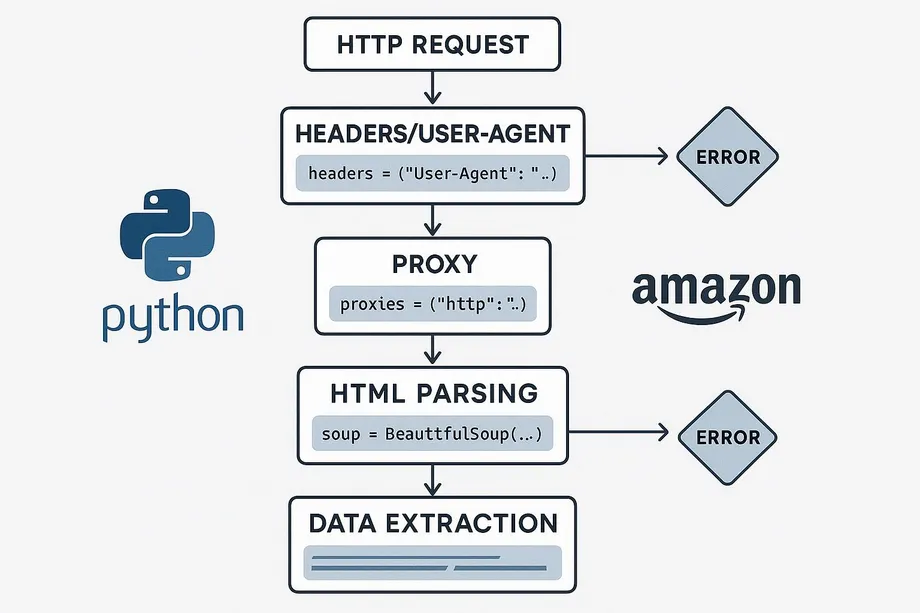
Method 1: The Traditional Approach - Python, Requests, and BeautifulSoup
This method involves scraping data directly from Amazon's web pages using the fundamental building blocks of web scraping. While this approach is excellent for understanding how the process works, it comes with significant challenges.
Step 1: Installing Required Libraries
First, we need the `requests` library for making HTTP requests and `BeautifulSoup` for parsing HTML.
pip install requests beautifulsoup4
Step 2: Making a Simple Request and the First Obstacle: Anti-Scraping Wall
Let's start by sending a simple GET request:
import requests
url = "https://www.amazon.com/dp/B098FKXT8L"
response = requests.get(url)
print(response.status_code)
print(response.text)
When you run this code, you'll most likely receive a `503` (Service Unavailable) status code instead of `200` (success), and instead of product information in the response content, you'll see a CAPTCHA or error message. This is because Amazon uses sophisticated systems to detect and block automated bots.
Step 3: Disguising Your Identity: User-Agent and Header Rotation
To convince Amazon that you're a real browser rather than a bot, you need to mimic the headers that a browser would send. The most important is the `User-Agent` header. Instead of using a single User-Agent, you can reduce the risk of detection by sending a different User-Agent with each request.
import random
user_agent_list = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/113.0'
]
headers = {
'User-Agent': random.choice(user_agent_list),
'Accept-Language': 'en-US,en;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Referer': 'https://www.google.com/'
}
Step 4: Overcoming IP Blocks: Using Proxies
Continuously sending numerous requests from the same IP address is the surest way to get blocked by Amazon. To overcome this, you need to use proxy servers to change your IP address with each request.
proxies = {
'http': 'http://username:[email protected]:8000',
'https': 'https://username:[email protected]:8000'
}
response = requests.get(url, headers=headers, proxies=proxies)
Step 5: Data Parsing
Assuming you've successfully overcome all obstacles and obtained the HTML content, it's time to extract the data we want using `BeautifulSoup`.
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Extract product title
title = soup.find('span', {'id': 'productTitle'}).get_text().strip()
# Extract product price
price = soup.find('span', {'class': 'a-price-whole'}).get_text().strip() + soup.find('span', {'class': 'a-price-fraction'}).get_text().strip()
print(f'Title: {title}')
print(f'Price: {price}')
The Endless Struggles of the Traditional Method
The steps above are just the tip of the iceberg. The real-world problems you'll encounter include:
- Constantly Changing HTML Structure: Amazon frequently changes its website structure. This means your `find` commands can stop working overnight. Your code requires constant maintenance.
- Dynamic Content: Some information like prices may be loaded later via JavaScript. The `requests` library cannot execute JavaScript, requiring you to use slower and more complex tools like `Selenium`.
- Advanced Bot Detection: Even the best proxy and header strategies can eventually become insufficient.
- Maintenance and Cost: Reliable proxy services are expensive, and managing all this infrastructure is a full-time job.

Method 2: The Smart and Fast Solution - Easyparser API
Wouldn't you rather set aside all this complexity, maintenance, and uncertainty and focus solely on the data? This is where Easyparser comes into play.
Easyparser is an API service that handles all the difficulties of extracting data from Amazon for you. Easyparser manages proxy rotation, header management, CAPTCHA solving, and changes in HTML structure. It simply provides you with clean, structured JSON data.
How Easy Is It to Extract Data with Easyparser?
Forget all the steps above. To extract the same product information with Easyparser, you only need to write this much code:
import requests
import json
# Set up the request parameters
params = {
'api_key': 'YOUR_API_KEY',
'platform': 'AMZ',
'domain': '.com',
'asin': 'B098FKXT8L',
'operation': 'DETAIL'
}
# Make the HTTP GET request to Easyparser API
api_result = requests.get('https://realtime.easyparser.com/v1/request', params)
# Print the JSON response from Easyparser API
print(json.dumps(api_result.json(), indent=2))
The response you'll receive is clean, structured JSON data:
{
"request_info": {
"success": true,
"credits_used": 1,
"credits_remaining": 99
},
"result": {
"detail": {
"asin": "B098FKXT8L",
"title": "Bose QuietComfort 45 Headphones",
"price": {
"value": 329.00,
"currency": "USD"
},
"availability": "In Stock"
}
}
}
Comparison: Traditional Method vs. Easyparser
| Feature | Traditional Method (Requests + BS4) | Easyparser API |
|---|---|---|
| Complexity | Very High (Header, Proxy, CAPTCHA management) | Very Low (Simple API request) |
| Reliability | Low (Frequently blocked) | Very High (99.9% success rate) |
| Maintenance | Continuous (Dependent on Amazon changes) | Zero (Easyparser handles all maintenance) |
| Speed | Slow (Proxy delays, retries) | Very Fast (Optimized infrastructure) |
| Focus | Focused on overcoming obstacles | Focused on analyzing data |
| Development Time | Weeks to months | Minutes to hours |
| Scalability | Limited (Infrastructure constraints) | Unlimited (Enterprise-grade infrastructure) |
Advanced Features with Easyparser
Easyparser offers much more than basic product data extraction:
Bulk Data Processing
Need to extract data from thousands of products? Easyparser's Bulk API can process up to 5,000 URLs in a single request:
bulk_request = {
'platform': 'AMZ',
'operation': 'DETAIL',
'domain': '.com',
'payload': {
'asins': ['B098FKXT8L', 'B08N5WRWNW', 'B08P3QVFMK']
},
'callback_url': 'https://your-app.com/webhook'
}
Geographic Targeting
Easyparser's Address Management system allows you to extract region-specific data, including local pricing and availability:
params = {
'api_key': 'YOUR_API_KEY',
'platform': 'AMZ',
'asin': 'B098FKXT8L',
'address_id': 'your_address_id', # For location-specific data
'operation': 'DETAIL'
}
Real-World Use Cases
Here are some practical applications where Easyparser excels:
- Price Monitoring: Track competitor prices across multiple marketplaces in real-time
- Inventory Management: Monitor stock levels and availability changes
- Market Research: Analyze product trends, reviews, and ratings
- Competitive Intelligence: Track competitor product launches and pricing strategies
- Dynamic Pricing: Implement automated repricing based on market conditions
Getting Started with Easyparser
Ready to simplify your Amazon data extraction? Here's how to get started:
- Sign Up: Create a free account at easyparser.com
- Get Your API Key: Access your API key from the dashboard
- Make Your First Request: Use the code examples above
- Scale Up: Choose a plan that fits your data needs
Conclusion: Your Time Is Valuable, Focus on Data
Extracting data from Amazon using Python can be a great exercise for learning the fundamentals of web scraping. However, when business gets serious and you need a reliable, scalable solution, the headaches and maintenance costs of traditional methods quickly escalate.
An API service like Easyparser frees you from infrastructural challenges and gives you back your most valuable asset: time. This way, you spend effort growing your business using that data, rather than collecting it. To transform data extraction from an engineering problem into a strategic advantage, try Easyparser for free today.
Stop fighting anti-bot systems and start focusing on what matters most: turning data into insights that drive your business forward.
Start extracting Amazon data for free
Start Your Free Trial100 free credits, no credit card required.