If you're trying to scrape Amazon data, you've probably hit a wall at some point. Maybe you started with something like Oxylabs thinking it would solve everything, only to realize it's not quite what you expected. I've been there too.
The thing is, most "Amazon scrapers" aren't really Amazon scrapers at all. They're proxy services that happen to work with Amazon pages. There's a big difference, and it matters more than you might think.
So What Makes an Amazon Scraper Different?
Let me break down what I've learned after years of working with Amazon data:
The Proxy Approach (What Oxylabs Does)
Oxylabs is fundamentally a proxy network. Their Amazon scraping is basically their general web scraper API with Amazon support tacked on. It works for simple stuff. You can get prices, titles, ratings. But when you need something deeper? You're stuck writing XPath selectors yourself, and even then, you'll only get what's visible on the page.
I've seen developers spend hours trying to extract data that just isn't there in the HTML. That's frustrating.
The Platform Approach (What We Built)
Easyparser isn't a proxy service trying to scrape Amazon. It's built specifically for Amazon data extraction from day one. We don't just parse HTML. Instead, we pull from the same data sources Amazon uses internally.
That means we can give you things like sales rank history, actual product dimensions (not just what's on the page), and sales trends over time. Stuff that generic scrapers simply can't access, no matter how good their XPath skills are.
Where Oxylabs Falls Short
Don't get me wrong. Oxylabs is great at what it does. Their proxy network is massive, and their general web scraper API works well for scraping random websites. But Amazon? That's where things get tricky.
When I tried using Oxylabs for Amazon data, here's what I found: it basically gives you the HTML, does some basic parsing, and that's it. You can get prices, titles, ratings. That's the obvious stuff. But try to get product dimensions for FBA calculations? Sales rank history? Actual sales volume trends? You're out of luck unless you build your own parser using their Custom Parser feature, which means writing XPath selectors yourself [1].
By the time you're done building that parser, you've essentially built your own scraper. At that point, why pay for Oxylabs?
What Makes Easyparser Different
We built Easyparser because we needed something that actually understood Amazon. Not just "can scrape Amazon pages" but "knows how Amazon works."
Instead of treating Amazon like any other website, we built it specifically for Amazon's ecosystem. That means we can access data sources that generic scrapers can't even see. We're not just parsing HTML. We're pulling from the same APIs and data feeds Amazon uses internally.
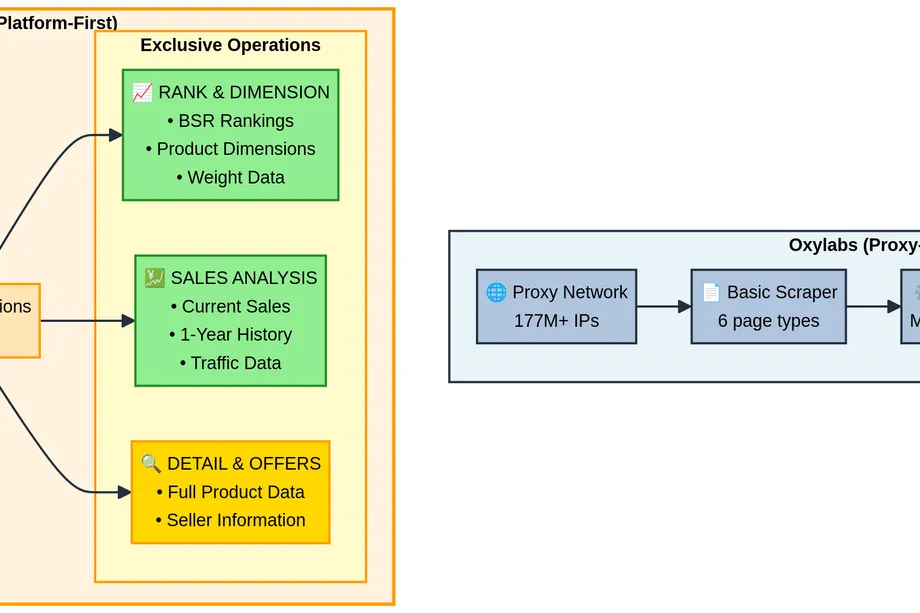
The Data You Actually Need
Here's the stuff that makes a real difference when you're working with Amazon data:
Rank & Dimension: Need to calculate FBA fees? You'll need the actual packaged dimensions and weight, not just what's displayed on the page. Our Rank & Dimension operation gives you BSR plus the real dimensions Amazon uses for logistics. This is the kind of data that saves you money when planning shipments.
Sales Analysis & History: Want to know if a product is trending up or down? Current price tells you nothing. But weekly sales data going back a year? That's what you need to spot trends, forecast demand, and understand whether a product is past its prime or just getting started.
Quick Comparison
Here's how they stack up side by side:
| Feature | Oxylabs (Web Scraper API) | Easyparser |
|---|---|---|
| Core Service | Proxy Provider with Generic Scraper | Specialized Amazon Data Platform |
| Data Depth | Surface-level (price, title, stock) | Deep & Analytical (sales history, dimensions) |
| Sales Rank (BSR) | ⌠Not Available | ✅ Available (Rank & Dimension Op) |
| Sales History | ⌠Not Available | ✅ Available (1-year weekly history) |
| Product Dimensions | ⌠Not Available | ✅ Available (for logistics) |
| Parsing | Basic automated, advanced requires manual XPath/CSS | Fully automated, structured JSON |
| Ease of Use | Requires technical configuration | Developer-friendly, plug-and-play |
| Pricing Model | Complex, variable per target | Simple, credit-based (1 credit = 1 result) |
How It Works in Practice
Use this operation to track product views and sales numbers in real time and get sales data going back up to 1 year:
import requests
import json
# Get sales analysis and history for a product
params = {
"api_key": "YOUR_API_KEY",
"platform": "AMZ",
"operation": "SALES_ANALYSIS_HISTORY",
"domain": ".com",
"asin": "B0FBF9NG2Y",
"history_range": "12"
}
# Execute the request
api_result = requests.get("https://realtime.easyparser.com/v1/request", params=params)
product_analytics = api_result.json()
print(json.dumps(product_analytics, indent=2))
Try all Easyparser operations for free with our demo package. Sign up now and start using your demo credits →
The Bottom Line
Look, if you just need to get past a captcha and scrape some basic HTML from Amazon pages, Oxylabs will do the job. But if you're trying to make actual business decisions like calculating FBA fees, tracking sales trends, or forecasting demand, you need data that goes deeper than what's on the page.
Easyparser isn't really an "Oxylabs alternative" in the traditional sense. It's a completely different tool for a completely different use case. If you need Amazon data, not just Amazon HTML, you need a platform built for Amazon. Everything else is just a workaround.
The Technical Case: Why Amazon Needs a Dedicated API
Amazon is not a typical website to scrape. Understanding why helps explain why generic proxy services like Oxylabs consistently underperform for Amazon-specific use cases.
Dynamic JavaScript Rendering
Amazon heavily uses client-side JavaScript to render content. Product prices, availability flags, and promotional badges often load asynchronously after the initial HTML response. A proxy service that retrieves raw HTML captures the page skeleton but frequently misses the dynamically injected data — resulting in missing prices, incomplete product details, or stale availability information.
Sophisticated Anti-Bot Detection
Amazon operates one of the most advanced bot detection systems on the internet. It analyzes request patterns, browser fingerprints, behavioral signals (mouse movements, click timing), TLS fingerprints, and dozens of other signals. Generic proxy rotators trigger detection at rates that would be catastrophic for production workflows. Easyparser maintains a 98.2% success rate by adapting its infrastructure continuously to Amazon's ever-changing detection mechanisms — a full-time engineering effort that no individual developer or generic proxy provider maintains.
Session and Geo-Targeting Complexity
Amazon shows different prices, availability, and product variants based on the shipping address associated with a session — not just the IP address. To scrape accurate regional pricing (critical for FBA pricing strategy or international arbitrage), you need persistent session management with address targeting, not just IP geo-routing. Easyparser provides address targeting on all plans; Oxylabs requires manual session handling and still only delivers IP-level geo-targeting.
Easyparser Operations You Cannot Get with Oxylabs
Here is a detailed look at four Easyparser operations that simply have no equivalent in the Oxylabs platform:
1. SALES_ANALYSIS_HISTORY — 1-Year Weekly Sales Data
This operation returns up to 52 weeks of weekly sales history for any ASIN. It is the foundation for demand forecasting, trend analysis, and identifying seasonal patterns — data that does not exist anywhere in Amazon's public-facing HTML.
import requests, json
# Get 12 months of weekly sales history
response = requests.get("https://realtime.easyparser.com/v1/request", params={
"api_key": "YOUR_API_KEY",
"platform": "AMZ",
"operation": "SALES_ANALYSIS_HISTORY",
"domain": ".com",
"asin": "B08N5WRWNW",
"history_range": "12" # weeks of history
})
history = response.json()["result"]["sales_history"]
for week in history:
print(f"Week of {week['date']}: {week['units_sold']} units")
2. RANK_AND_DIMENSION — BSR + Actual Logistics Dimensions
Returns the Best Sellers Rank for all relevant categories plus the real packaged dimensions Amazon uses for FBA fee calculations — not the 'product dimensions' shown on the detail page, but the actual box dimensions used by Amazon's warehouse system. This is critical for accurate FBA profitability calculations.
response = requests.get("https://realtime.easyparser.com/v1/request", params={
"api_key": "YOUR_API_KEY",
"platform": "AMZ",
"operation": "RANK_AND_DIMENSION",
"domain": ".com",
"asin": "B08N5WRWNW"
})
data = response.json()["result"]
print(f"BSR: #{data['rank']['bsr']} in {data['rank']['category']}")
print(f"Packaged: {data['dimensions']['length']}" x {data['dimensions']['width']}" x {data['dimensions']['height']}")
3. SELLER_PROFILE — Full Seller Storefront Data
Returns complete seller metrics including ratings, review count, response time, and storefront product listings. Oxylabs cannot access seller-level data through its proxy approach since this data requires authenticated sessions and specific API endpoints.
response = requests.get("https://realtime.easyparser.com/v1/request", params={
"api_key": "YOUR_API_KEY",
"platform": "AMZ",
"operation": "SELLER_PROFILE",
"domain": ".com",
"seller_id": "A1Z83G675VNOF7"
})
seller = response.json()["result"]
print(f"Seller: {seller['name']} | Rating: {seller['rating']} | {seller['review_count']} reviews")
Pricing Deep Dive: Oxylabs vs Easyparser at Scale
Here is a transparent monthly cost comparison at different usage volumes, using the closest matching tier from each provider:
| Monthly Volume | Easyparser | Oxylabs (Web Scraper API) | Easyparser Advantage |
|---|---|---|---|
| 10,000 requests | $49 (Beginner: 100K) | $49 (Micro: 98K) | Same price — but Easyparser includes Amazon-specific ops |
| 100,000 requests | $49 (Beginner: 100K) | $99 (Starter: 220K) | 50% cheaper + bulk API + webhooks |
| 500,000 requests | $300 (Advanced: 750K) | $249 (Advanced: 622K) | Comparable price — Easyparser adds 128K more requests + sales history |
| 1,000,000 requests | ~$600 (2x Advanced) | ~$498 (2x Advanced) | Oxylabs slightly cheaper at scale — but cannot match data depth |
The pricing story is clear at low-to-mid volumes: Easyparser is meaningfully cheaper at 100K requests/month and comparable at 500K. At 1M+, Oxylabs has a slight price edge — but the question becomes whether you need generic proxy infrastructure or Amazon-specific data depth. For teams building Amazon-focused products, the $100/month difference at scale is typically dwarfed by the engineering cost of building workarounds for missing data.
Real Developer Use Cases
Use Case 1: E-Commerce Price Monitoring Startup
A two-person startup built a price comparison tool for Amazon products across 15 marketplaces. They initially tried Oxylabs but spent 6 weeks building custom XPath parsers that broke every few days as Amazon updated its page structure. After switching to Easyparser's DETAIL operation, they eliminated the parsing layer entirely. The Bulk API now processes 50,000 ASIN price checks per night as a single bulk job with webhook delivery — at a cost of $300/month (Advanced tier). Their engineering team now focuses on the product rather than scraper maintenance.
Use Case 2: FBA Seller Optimizing Inventory and Fees
An individual seller managing 200 private label SKUs needed accurate FBA fee calculations to optimize pricing. The RANK_AND_DIMENSION operation delivers the exact packaged dimensions Amazon uses for fee calculations — data that was previously obtained by physically measuring boxes in a fulfillment center or paying for expensive third-party tools. Combined with SALES_ANALYSIS_HISTORY to track weekly demand patterns, the seller reduced overstock by 23% in three months by identifying which products had declining sales velocity before inventory commitments were made.
Use Case 3: Market Research Firm Analyzing Consumer Electronics
A market research firm tracks 8,000 ASINs across the consumer electronics category for a Fortune 500 client. Using Easyparser's Bulk API with webhook delivery, they run weekly category snapshots that capture pricing, availability, bought-in-past-month data, and BSR for every tracked product. The entire weekly run completes in under 2 hours at a 98.2% success rate — compared to their previous Oxylabs setup which required 14+ hours of sequential requests and delivered partial data due to anti-bot detection failures.
References
[1] Oxylabs. (n.d.). Web Scraper API. Retrieved from: https://oxylabs.io/products/scraper-api
[2] Easyparser Documentation. (n.d.). Advanced Operations. Retrieved from: https://easyparser.gitbook.io/easyparser-documentation/real-time-integration
Try the best-rated Amazon API for free
Start Your Free Trial100 free credits, no credit card required.