Choosing the right tool for web scraping can be a daunting task for developers. With a plethora of options available, two of the most popular Python libraries that often come up in discussion are Scrapy and BeautifulSoup. Both are powerful in their own right, but they serve different purposes and are suited for different types of projects. This guide will provide a comprehensive comparison of Scrapy and BeautifulSoup, helping you decide which tool is the best fit for your web scraping needs in 2025. We will also explore how modern solutions like Easyparser can simplify the entire process, eliminating the need for complex setups and maintenance.
What is BeautifulSoup?
BeautifulSoup is a Python library designed for pulling data out of HTML and XML files. It works with your favorite parser to provide idiomatic ways of navigating, searching, and modifying the parse tree. It's a versatile tool that can save developers hours or even days of work.
Key Features of BeautifulSoup:
- **Simplicity:** BeautifulSoup is known for its simple and intuitive API, making it easy to learn and use, even for beginners.
- **Flexibility:** It can be integrated with other libraries like `requests` to fetch web pages, giving you more control over the scraping process.
- **Lightweight:** BeautifulSoup is a lightweight library that is easy to install and has minimal dependencies.
- **Excellent for Parsing:** It excels at parsing messy and poorly structured HTML, making it a robust choice for a wide range of websites.
BeautifulSoup Code Example:
import requests
from bs4 import BeautifulSoup
URL = "http://quotes.toscrape.com/"
page = requests.get(URL)
soup = BeautifulSoup(page.content, "html.parser")
quotes = soup.find_all("span", class_="text")
for quote in quotes:
print(quote.text)
Best Use Cases for BeautifulSoup:
- Quick and simple scraping tasks.
- Small to medium-sized projects.
- Parsing already downloaded HTML files.
- When you need a high degree of flexibility and control over the scraping process.
Advantages and Limitations of BeautifulSoup:
Advantages:
- Easy to learn and use.
- Flexible and can be combined with other libraries.
- Excellent at handling malformed HTML.
Limitations:
- Not a complete scraping framework; requires other libraries for fetching web pages.
- Slower for large-scale projects as it processes requests synchronously.
- Lacks built-in features for handling common scraping tasks like following links or managing sessions.
What is Scrapy?
Scrapy is a powerful and fast web scraping framework for Python. It provides a complete solution for scraping websites, from fetching pages to extracting and storing data. Scrapy is built on top of Twisted, an asynchronous networking framework, which allows it to handle a large number of requests concurrently.
Key Features of Scrapy:
- **Complete Framework:** Scrapy is a full-fledged framework that includes all the tools you need for web scraping, including a built-in web crawler.
- **Asynchronous:** It can handle multiple requests simultaneously, making it much faster than synchronous libraries like BeautifulSoup for large-scale projects.
- **Extensible:** Scrapy has a rich ecosystem of extensions and middleware that can be used to add new functionality.
- **Built-in Data Processing:** It includes built-in support for processing and storing scraped data in various formats.
Scrapy Code Example:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = ["http://quotes.toscrape.com/"]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
for quote in response.css("div.quote")
yield {
"text": quote.css("span.text::text").get(),
"author": quote.css("small.author::text").get(),
}
Best Use Cases for Scrapy:
- Large-scale and complex web scraping projects.
- When you need to crawl multiple pages of a website.
- Building automated scraping pipelines.
- Production-level scraping applications.
Advantages and Limitations of Scrapy:
Advantages:
- Fast and efficient due to its asynchronous architecture.
- A complete framework with built-in crawling and data processing capabilities.
- Highly extensible and has a large community.
Limitations:
- Steeper learning curve compared to BeautifulSoup.
- More complex to set up and configure.
- Can be overkill for simple scraping tasks.
Head-to-Head Comparison: Scrapy vs. BeautifulSoup
| Feature | Scrapy | BeautifulSoup |
|---|---|---|
| **Type** | Web Scraping Framework | HTML/XML Parsing Library |
| **Speed** | Fast (Asynchronous) | Slower (Synchronous) |
| **Ease of Use** | Steeper learning curve | Easy to learn and use |
| **Scalability** | Highly scalable | Less scalable for large projects |
| **Built-in Features** | Crawling, data processing, pipelines | Parsing only |
| **Community** | Large and active | Large and active |
| **Use Cases** | Large-scale, complex projects | Small to medium-sized, simple tasks |
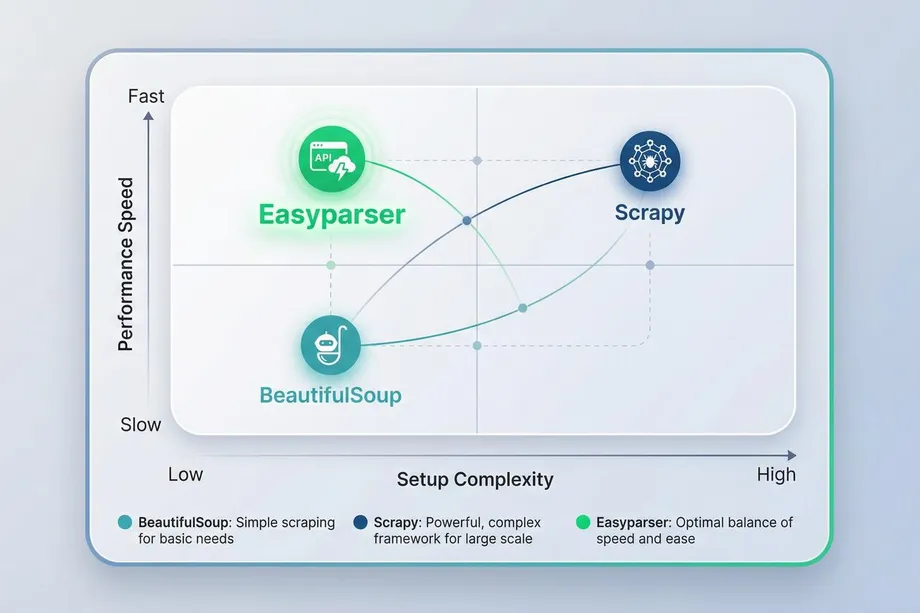
Visual comparison of setup complexity and performance speed across different web scraping tools
When to Use Each Tool
The choice between Scrapy and BeautifulSoup ultimately depends on the specific requirements of your project. Here’s a simple decision framework:
- **For quick, one-off scraping tasks or small projects:** BeautifulSoup is the ideal choice. Its simplicity and flexibility allow you to get the job done with minimal setup and code.
- **For large-scale, complex projects that require crawling multiple pages and handling a large volume of data:** Scrapy is the clear winner. Its asynchronous architecture, built-in crawling capabilities, and extensible nature make it the perfect tool for building robust and efficient scraping pipelines.
The Challenge: Complex Setup and Maintenance
While both Scrapy and BeautifulSoup are powerful tools, they come with their own set of challenges. Both require a significant amount of coding and maintenance. You need to write code to handle HTML parsing, data extraction logic, and data structuring. This can be a time-consuming and error-prone process, especially when dealing with complex websites that frequently change their layout.
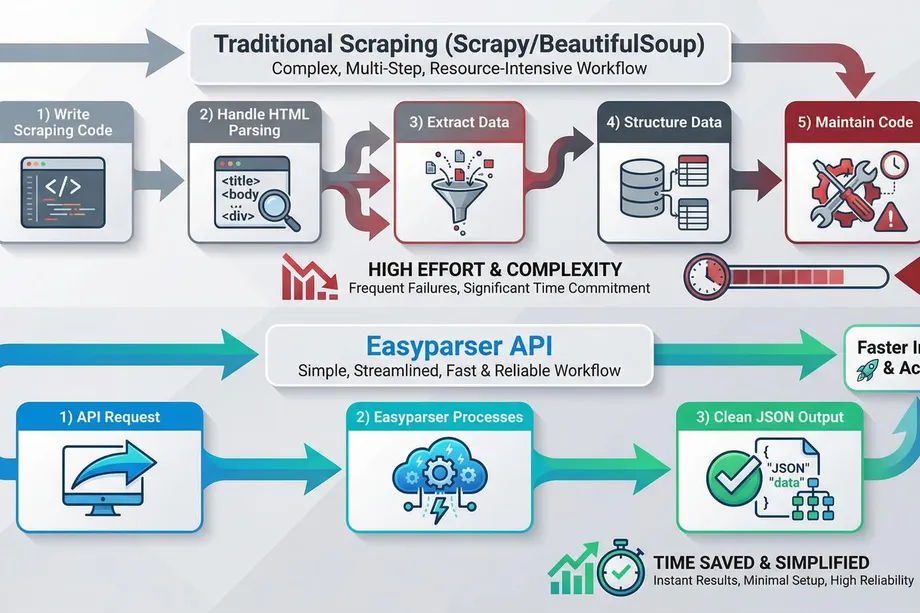
Traditional scraping workflow vs. simplified Easyparser API approach
Simplify Web Scraping with Easyparser
This is where Easyparser comes in. Easyparser is a web scraping API that simplifies the entire process of data extraction. Instead of writing and maintaining complex scraping code, you can simply make an API call to Easyparser and get the data you need in a clean, structured JSON format.
The Easyparser Advantage: Direct JSON Output
The biggest advantage of Easyparser is that it provides direct JSON output. You don't have to worry about parsing HTML, extracting data, or structuring it into a usable format. Easyparser handles all the complexity for you, allowing you to focus on what you do best: building amazing applications with the data you collect.
Easyparser Real-Time API Example:
import requests
url = "https://realtime.easyparser.com/v1/request?api_key=YOUR_API_KEY&platform=AMZ&operation=DETAIL&output=json&domain=.com&asin=B0D4215HCX"
response = requests.get(url)
data = response.json()
print(data)
Easyparser Bulk API Example:
import requests
payload = {
"platform": "AMZ",
"operation": "DETAIL",
"domain": ".com",
"webhook_url": "https://your-domain.com/webhook",
"data": [
{"asin": "B0F25371FH"},
{"asin": "B08N5WRWNW"},
{"asin": "B0BSHF7WHW"}
]
}
response = requests.post("https://bulk.easyparser.com/v1/request", json=payload)
result = response.json()
print(f"Bulk request ID: {result['request_id']}")
Conclusion
Both Scrapy and BeautifulSoup are excellent tools for web scraping, but they are designed for different purposes. BeautifulSoup is perfect for quick and simple tasks, while Scrapy excels at large-scale, structured projects. However, both require a significant amount of coding and maintenance. If you're looking for a simpler and more efficient way to scrape the web, Easyparser is the perfect solution. With its direct JSON output and powerful real-time and bulk APIs, Easyparser takes the complexity out of web scraping, allowing you to get the data you need with minimal effort.
Ready to simplify your web scraping workflow? Start your free trial of Easyparser today!
Try the best-rated Amazon API for free
Start Your Free Trial100 free credits, no credit card required.