In the rapidly evolving landscape of e-commerce, access to accurate and timely data is the ultimate competitive advantage. For businesses relying on Amazon - whether as sellers, brands, or market researchers - the choice of data extraction tools directly impacts profitability. Today, we are comparing two prominent solutions in the market: Easyparser and Nimble. While Nimble offers a broad web scraping API, this comprehensive guide will explore why a specialized amazon scraping api like Easyparser often delivers superior value, better data quality, and significantly lower costs for Amazon-focused operations in 2026.
Easyparser vs Nimble: Quick Comparison Table
Before diving deep into each aspect, here is a high-level overview of how easyparser vs nimble stacks up across the most critical dimensions for Amazon data extraction teams:
| Feature | Easyparser | Nimble |
|---|---|---|
| Primary Focus | Amazon-exclusive API | General web scraping |
| Entry Price | $49/mo (100K credits) | $150/mo (150 credits) |
| Cost per 1K results | $0.43 - $0.49 | $1.60 - $3.00 |
| Free Tier | 100 credits/month (no card) | 7-day trial (5K pages) |
| Dedicated Amazon Operations | 10 operations | None (generic scraping) |
| Sales Analysis & History | Yes (dedicated endpoint) | No |
| Package Dimension API | Yes (dedicated endpoint) | No |
| Real-Time API | Yes (~7.5s response) | Yes (general) |
| Bulk/Async API | Yes (webhook delivery) | Yes (batch processing) |
| Address Targeting | Yes (zip-code level) | No |
| JSON Output | Amazon-structured JSON | AI-parsed generic JSON |
| Success Rate (claimed) | High (Amazon-optimized) | 98%+ (general) |
The Core Difference: General Web Scraping vs. Specialized Amazon Data Extraction
Before analyzing the technical benchmarks and pricing comparisons, it is crucial to understand the fundamental architectural differences between Easyparser and Nimble.
Nimble, which older sources and reviews may still refer to as Nimbleway, provides a powerful, general-purpose web scraping platform. Their infrastructure is designed to handle a wide variety of websites, utilizing AI-powered parsing to extract data from raw HTML. This makes Nimble a versatile tool if your data needs span across hundreds of different, unrelated domains. Their platform is particularly strong for enterprise teams that need to collect data from multiple sources simultaneously, and their residential proxy network is one of the most robust in the industry.
Conversely, Easyparser is purpose-built exclusively for Amazon. Every component of the Easyparser infrastructure - from proxy rotation and anti-bot evasion to data parsing and JSON structuring - is optimized specifically for Amazon's unique architecture. This specialization allows Easyparser to offer 10 distinct, dedicated Amazon data operations, ensuring that users receive deep, highly structured, and consistently reliable data that generic scrapers simply cannot match. When you are running an amazon scraping api workflow at scale, this specialization translates directly into fewer failed requests, less post-processing overhead, and more actionable data.

Pricing Model: Credits vs. Subscription Tiers
Pricing is often the deciding factor for businesses scaling their data operations. When comparing easyparser vs nimble, the differences in cost structure are stark and heavily favor the specialized approach.
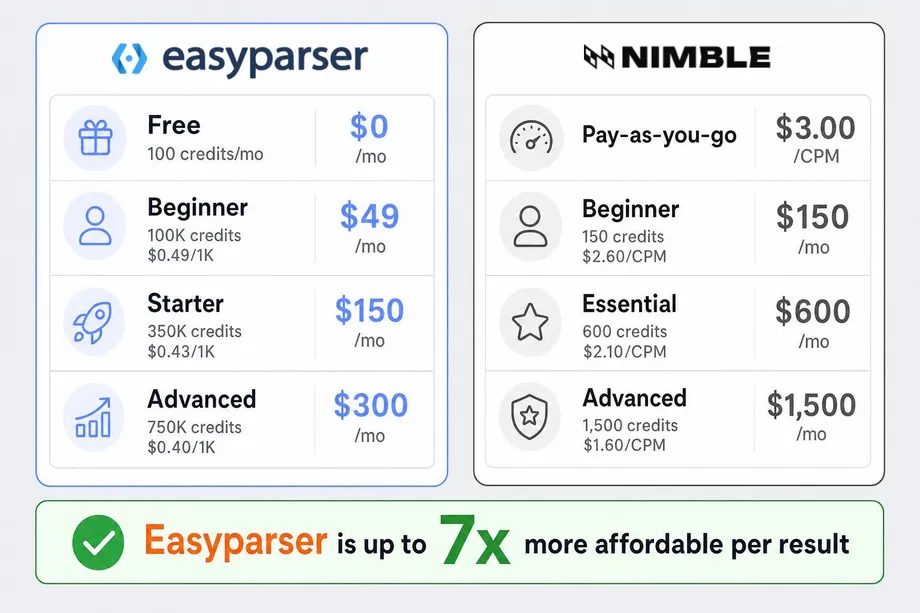
Nimble operates on a standard web scraping pricing model where costs are calculated per 1,000 pages scraped (CPM). Their Pay-As-You-Go rate is $3.00/CPM. To access lower rates, users must commit to substantial monthly subscriptions: $150 for the Beginner plan ($2.60/CPM), $600 for Essential ($2.10/CPM), and $1,500 for Advanced ($1.60/CPM). These rates reflect the cost of general-purpose infrastructure that must handle any website on the internet.
Easyparser, on the other hand, utilizes a transparent, 1:1 credit system where 1 credit equals 1 successful product result, with no hidden multipliers. The pricing is remarkably more accessible for Amazon-focused teams:
- Free Tier: 100 credits every month, no credit card required. Ideal for testing and development.
- Beginner Plan: $49/month for 100,000 credits ($0.49 per 1,000 results). Perfect for small projects and startups.
- Starter Plan: $150/month for 350,000 credits ($0.43 per 1,000 results). The best value package for growing businesses.
- Advanced Plan: $300/month for 750,000 credits ($0.40 per 1,000 results). Designed for scaling operations.
At the $150/month price point, Nimble provides approximately 57,000 page requests, whereas Easyparser delivers 350,000 structured product results. This means Easyparser is up to 7x more affordable for Amazon data extraction, allowing businesses to scale their operations without breaking the bank. For a company processing 1 million product lookups per month, this pricing difference alone can represent savings of over $1,700 monthly compared to Nimble's Essential plan.
Amazon-Specific Features: What Each API Offers
The true value of an amazon scraping api lies in the depth of data it can reliably extract. Generic scrapers often struggle to pull complex, nested data points from Amazon listings, especially when Amazon updates its page structure or introduces new anti-scraping measures.
Nimble's general parsing engine can successfully extract basic product information such as titles, prices, and top-level reviews. However, because it is not exclusively tailored to Amazon, it lacks dedicated endpoints for more granular e-commerce metrics. Teams using Nimble for Amazon data often find themselves writing and maintaining custom parsing logic to handle edge cases, variant products, and dynamic content sections.
Easyparser provides 10 dedicated operations through its Amazon Scraping API that cover every aspect of the Amazon ecosystem. Notably, it includes exclusive features that are critical for serious sellers and market analysts:
- Sales Analysis and History: Track historical sales performance and pricing trends over time, a feature completely absent in generic scrapers. This data is invaluable for sellers evaluating product viability before launching.
- Package Dimension: Crucial for FBA sellers calculating shipping and storage costs accurately. Knowing exact package dimensions helps optimize fulfillment strategies and avoid unexpected fees.
- Product Detail: Comprehensive extraction of all variations, high-resolution image URLs, bullet points, A+ content indicators, and complete attribute sets.
- Best Sellers Rank (BSR): Track product category rankings to evaluate market positioning and demand velocity across multiple categories simultaneously.
- Seller Profile and Feedback: Deep seller intelligence including feedback scores, response rates, and seller history - critical for buyers evaluating third-party sellers and for brands monitoring unauthorized resellers.
This level of specialization ensures that whether you are conducting competitor analysis, managing inventory, or building a price intelligence platform, you have the exact data points required to make informed decisions without any additional parsing overhead on your end.
Success Rate and Response Time Benchmark
When executing thousands of requests daily, success rates and latency are paramount. Both Easyparser and Nimble boast high success rates, typically exceeding 98%. However, the way they handle requests differs significantly based on their architectural approach.
Nimble utilizes a robust residential proxy network to ensure high deliverability, and their AI-driven fingerprinting technology helps bypass anti-bot measures on general websites. Nimble's own materials highlight very low response-time figures for its scraping infrastructure, but third-party benchmarks can look different for Amazon specifically. For example, Proxyway's Web Scraping API Report 2025 reported a 10.26-second Amazon response time for Nimble in its test setup. This is why vendor metrics should be treated as claims and external benchmarks as point-in-time evidence rather than universal guarantees.
Easyparser offers two distinct integration methods tailored to different operational needs, giving developers precise control over how they consume the amazon scraping api:
1. Real-Time API: Designed for synchronous operations where immediate data is required, such as live pricing dashboards, dynamic repricing tools, or real-time inventory checks. The Real-Time API delivers fully structured JSON responses in approximately 7.5 seconds, navigating Amazon's anti-bot defenses seamlessly. This is the right choice for applications where a user is waiting for a response.
2. Bulk API: For large-scale data extraction such as updating a catalog of 50,000 ASINs or running a nightly competitive analysis sweep, the asynchronous Bulk API is the optimal choice. You submit a batch of ASINs in a single request, and Easyparser processes them efficiently in the background, delivering the structured JSON data directly to your server via Webhook. This ensures your application threads are not blocked waiting for synchronous HTTP responses, dramatically improving throughput for high-volume workflows.
Anti-Bot Capabilities: How Each Handles Amazon's Defenses
Amazon employs some of the most sophisticated anti-scraping technology in the e-commerce industry. Understanding how each API handles these defenses is critical for ensuring data pipeline reliability.
Nimble's approach relies on their AI-managed residential proxy network, which rotates IP addresses and mimics human browsing patterns across millions of IPs. This is effective for general web scraping but requires ongoing calibration as Amazon updates its detection algorithms. Since Nimble is not exclusively focused on Amazon, their anti-bot tuning is necessarily more generalized.
Easyparser's entire infrastructure is tuned specifically for Amazon's detection systems. The platform handles cookie management, session rotation, and request timing in a way that is specifically calibrated for Amazon's current anti-bot stack. This means that as Amazon updates its defenses, Easyparser's team can respond with targeted countermeasures rather than broad adjustments. For teams that have experienced frequent blocks or CAPTCHAs with general-purpose scrapers, switching to a dedicated easyparser vs nimble evaluation often reveals a significant improvement in reliability.
Real-Time vs. Bulk API: Which Has Better Support?
Both Easyparser and Nimble support synchronous and asynchronous data retrieval, but the implementation quality and use-case alignment differ considerably.
Nimble's batch processing capability is designed for general web crawling at scale. It works well for processing large queues of diverse URLs but does not offer Amazon-specific optimizations for batch operations. There is no native webhook delivery system for Amazon-specific result sets.
Easyparser's dual-API architecture is a deliberate design choice that reflects the real-world needs of Amazon data teams. The Real-Time API is optimized for low-latency, on-demand lookups, while the Bulk API is built for high-throughput, scheduled data pipelines. Both APIs return the same standardized JSON schema, meaning your data processing code works identically regardless of which integration method you use. This consistency simplifies engineering and reduces the risk of schema-related bugs in production.
Below is a practical example of how to use the Easyparser Bulk API to submit a batch of ASINs for asynchronous processing:
import requests
API_KEY = "YOUR_API_KEY"
WEBHOOK_URL = "https://your-server.com/webhook/easyparser"
payload = {
"api_key": API_KEY,
"platform": "AMZ",
"operation": "DETAIL",
"domain": ".com",
"webhook_url": WEBHOOK_URL,
"asins": ["B098FKXT8L", "B07XJ8C8F5", "B09G9FPHY6"]
}
response = requests.post("https://bulk.easyparser.com/v1/request", json=payload)
print(response.json()) # Returns job_id for tracking
Data Quality: Structured JSON Output Comparison
When evaluating an amazon scraping api, the quality and structure of the output data are just as important as the extraction speed. Nimble provides a generalized output that, while useful, often requires secondary processing to map the data to e-commerce specific database schemas. Teams frequently need to write transformation layers to normalize Nimble's output into the specific fields their applications expect.
Easyparser's JSON response is meticulously crafted for e-commerce applications. Every data point - from the Buy Box winner and fulfillment channel (FBA vs. FBM) to detailed variant matrices and high-resolution image arrays - is pre-structured in a consistent schema. This eliminates the need for complex data transformation pipelines on your end, allowing your engineering team to focus on building product features rather than cleaning and normalizing raw data.
For buyers, this means that product comparison engines, price trackers, and catalog management systems can ingest Easyparser data directly without intermediate processing steps. For sellers, the structured output from operations like Sales Analysis and History provides ready-to-use time-series data that can be fed directly into analytics dashboards or inventory forecasting models.
Developer Experience: Documentation and SDKs
A seamless developer experience accelerates time-to-market. Both platforms offer extensive documentation, but Easyparser's focus on Amazon simplifies the integration process dramatically.
With Easyparser, developers do not need to write custom parsing logic or maintain CSS selectors. The API expects standard parameters (like ASIN and domain) and returns predictable, heavily structured JSON. Furthermore, Easyparser supports advanced features like Address Targeting, allowing you to specify the exact delivery zip code to extract accurate, localized pricing and shipping data - a critical requirement for accurate competitive pricing analysis across different geographic markets.
The Easyparser documentation covers all 10 operations with detailed field descriptions, sample requests, and sample responses. Code examples are available in Python, Node.js, PHP, Go, C#, and Java, making it accessible to development teams regardless of their technology stack. The API Playground allows developers to test requests directly in the browser before writing a single line of code, reducing the time from signup to first successful data extraction to under 10 minutes.
Below is an example of how simple it is to integrate Easyparser using Python for real-time product data extraction:
import requests
API_KEY = "YOUR_API_KEY" # Get your key from app.easyparser.com
ASIN = "B098FKXT8L"
params = {
"api_key": API_KEY,
"platform": "AMZ",
"operation": "DETAIL",
"asin": ASIN,
"domain": ".com"
}
response = requests.get("https://realtime.easyparser.com/v1/request", params=params)
data = response.json()
product = data.get("product", {})
print(f"Title: {product.get('title')}")
print(f"Price: ${product.get('price')}")
print(f"Rating: {product.get('rating')} stars")
Verdict: When to Choose Easyparser Over Nimble
Choosing the right tool depends entirely on your specific business requirements. If your company needs to scrape data from thousands of different websites across various industries - news sites, social media platforms, financial portals, and e-commerce sites simultaneously - Nimble's generalized web scraping capabilities and residential proxy network make it a strong contender for that use case.
However, if your primary focus is Amazon, or if you are looking for a Nimble alternative for Amazon, the choice is clear. For e-commerce brands, dropshippers, market intelligence firms, and Amazon sellers, Easyparser is the definitive solution. The combination of 10 Amazon-exclusive data operations, a transparent 1:1 credit model that is up to 7x more affordable than Nimble, dedicated Real-Time and Bulk API integrations, and address-level geo-targeting makes Easyparser the most cost-effective and feature-rich amazon scraping api available in 2026.
The easyparser vs nimble comparison ultimately comes down to specialization versus generalization. For Amazon data at scale, specialization wins every time. Start with Easyparser's free tier today and experience the difference that purpose-built infrastructure makes for your data pipeline.
Start monitoring your competitors for free
Start Your Free Trial100 free credits, no credit card required.