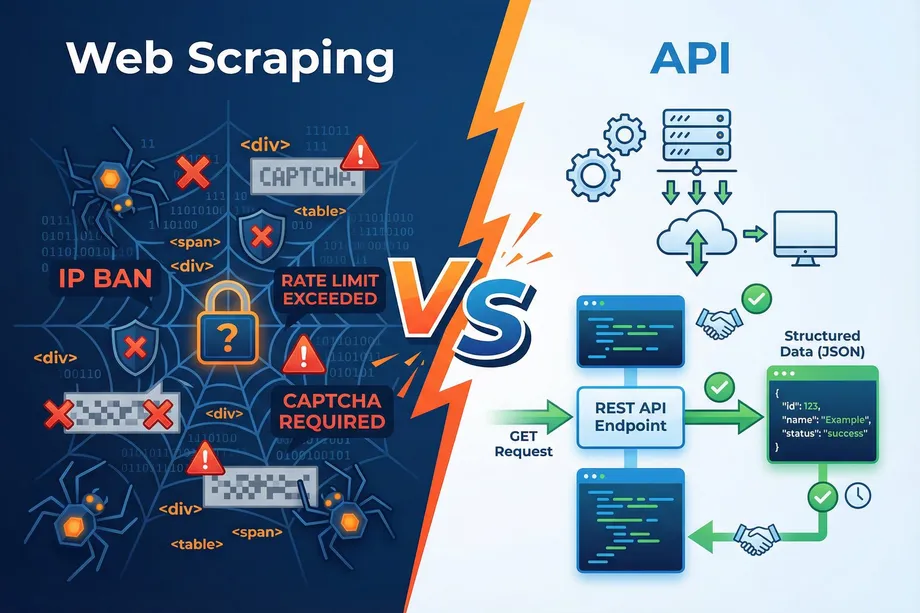
In the rapidly evolving landscape of data extraction, choosing between web scraping vs api integration is one of the most critical decisions a developer, data analyst, or e-commerce business must make. As we navigate through 2026, the demand for structured, reliable, and real-time data has never been higher. Whether you are an Amazon seller tracking competitor prices or a data scientist building market models, the method you choose to acquire data will fundamentally impact your project's success, scalability, and maintenance costs.
This comprehensive guide explores the nuances of web scraping vs api approaches, dissecting their advantages, limitations, and ideal use cases. We will examine the hidden complexities of building DIY scrapers, the structured reliability of APIs, and how modern solutions are bridging the gap between the two methodologies.
Understanding the Core Differences: Web Scraping vs API
At its core, the web scraping vs api debate centers on how you interact with a target platform's infrastructure. An API (Application Programming Interface) is an official, structured channel provided by a platform to access its data. It operates under defined rules, rate limits, and response formats, typically delivering clean JSON or XML data. Think of an API as a dedicated service window where you request specific items and receive them neatly packaged.
Conversely, web scraping involves writing automated scripts that navigate web pages exactly as a human user would via a browser. The scraper downloads the raw HTML content and parses it to extract the desired information. This method is akin to walking into a store, looking at the shelves, and writing down the prices and product details yourself. While highly flexible, it relies entirely on the visual structure of the website remaining consistent.
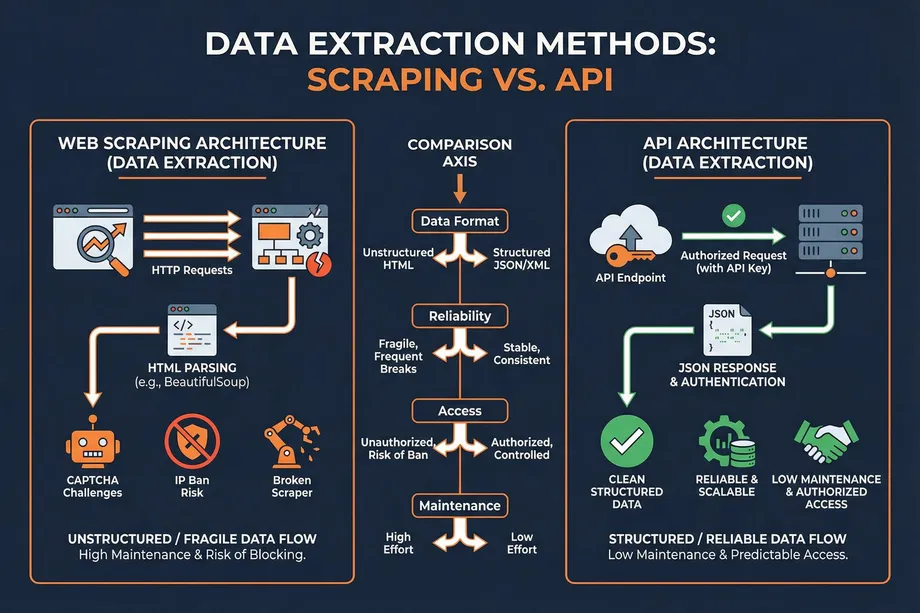
The Allure and Challenges of DIY Web Scraping
For many developers, DIY web scraping is the initial gateway into data extraction. Tools like Python's BeautifulSoup, Selenium, or Playwright offer immense power to pull data from virtually any publicly accessible webpage. The primary advantage of this approach is absolute flexibility; if you can see the data on your screen, you can scrape it.
However, the reality of maintaining web scrapers in production environments is fraught with challenges. Modern websites, particularly e-commerce giants like Amazon, employ sophisticated anti-bot mechanisms. When evaluating web scraping vs api, one must consider the ongoing battle against CAPTCHAs, IP bans, and browser fingerprinting.
Furthermore, websites frequently update their DOM structures. A simple class name change or layout redesign can instantly break a scraping script, leading to missing data and urgent maintenance requirements. For businesses relying on continuous data flow, the hidden costs of proxy management, server infrastructure, and developer hours dedicated to fixing broken scrapers often outweigh the perceived benefits of a "free" DIY solution.
The Advantages of API-Based Data Extraction
When comparing web scraping vs api, APIs consistently win in terms of stability, speed, and data structure. An official API provides a contractual agreement between the data provider and the consumer. The response schemas are documented and stable, meaning your application can reliably parse the incoming JSON data without fear of unexpected structural changes.
APIs are also significantly faster. Because they bypass the need to download heavy HTML, CSS, and JavaScript files, APIs transmit only the raw data requested. This efficiency allows for high-volume, concurrent requests, which is essential for enterprise-scale operations.
However, official APIs often come with limitations. They may restrict access to certain data points, impose strict rate limits, or charge exorbitant fees for high-volume usage. In scenarios where the official API does not provide the necessary depth of data, businesses often find themselves forced back into the complexities of web scraping.
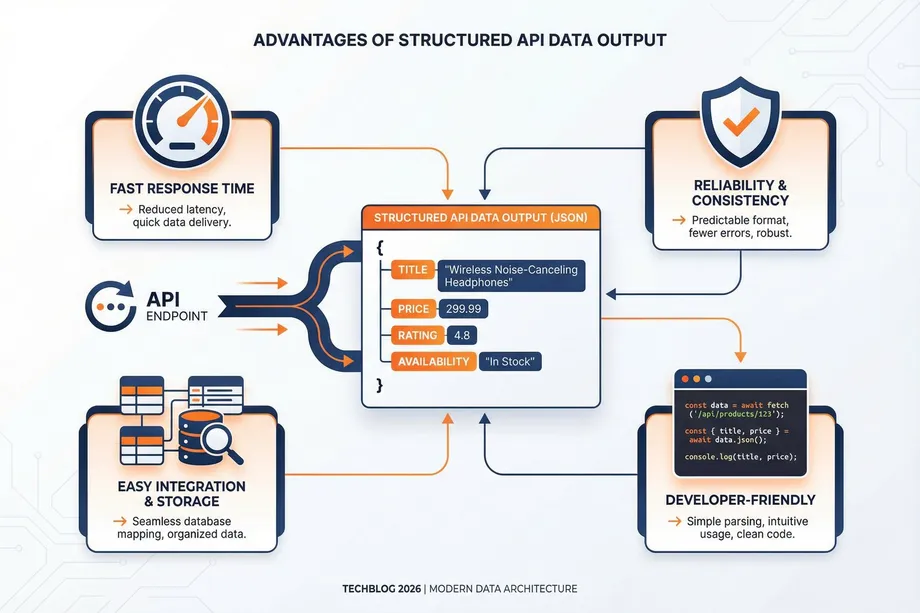
Decision Framework: Which Method Is Right for Your Project?
Determining the winner in the web scraping vs api comparison depends entirely on your specific use case, technical resources, and budget. Here is a framework to guide your decision:
| Criteria | Choose Web Scraping When... | Choose API When... |
|---|---|---|
| Data Availability | The target site does not offer an official API, or the API lacks required data points. | The official API provides all the necessary data fields. |
| Budget | You have developer resources but a limited budget for third-party services. | You prefer predictable costs and want to minimize ongoing maintenance expenses. |
| Maintenance Capacity | You have a dedicated team ready to fix scripts when website structures change. | You require a "set it and forget it" solution with guaranteed uptime. |
| Scale and Speed | You need to extract data from thousands of different, smaller websites. | You need high-volume, rapid extraction from a single, complex platform. |
Web Scraping vs API: Real-World Use Cases
To contextualize the web scraping vs api debate, let's examine how different roles utilize these methods.
For E-commerce Sellers: Market Intelligence
Sellers need comprehensive data to remain competitive. While they might use a platform's official API for managing their own inventory, gathering competitive intelligence-such as monitoring competitor prices, tracking Buy Box winners, or analyzing customer reviews-often requires data points not exposed through official seller APIs. In these cases, a robust scraping solution becomes essential to gain a complete market overview.
For Data Analysts: Building Predictive Models
Data analysts require vast, clean datasets to build accurate models. Dealing with the inconsistencies of raw HTML scraping can consume a significant portion of an analyst's time. Therefore, analysts strongly prefer API-based solutions that deliver structured JSON data, allowing them to focus on analysis rather than data cleaning and extraction engineering.

The Modern Solution: Web Scraping APIs
The ultimate resolution to the web scraping vs api dilemma is the emergence of specialized Web Scraping APIs. These services combine the comprehensive data access of web scraping with the structured reliability of an API. Instead of managing proxies, solving CAPTCHAs, and updating parsers, you simply make an API call to a third-party service, which handles the complex scraping infrastructure behind the scenes and returns clean JSON data.
For platforms with notoriously difficult anti-bot measures, like Amazon, a dedicated scraping API is often the most viable solution. It abstracts away the technical hurdles, allowing businesses to access real-time, geo-localized data at scale.
For instance, Easyparser operates precisely on this model. As a dedicated Amazon data extraction API, it resolves the core conflicts of the web scraping vs api debate. By providing endpoints for operations like Product Detail, Product Offer, and Sales Analysis & History, Easyparser delivers the depth of scraped data with the speed and reliability of an enterprise API.
Here is how simple it is to extract comprehensive product details using Easyparser's real-time API:
import requests
API_KEY = "YOUR_API_KEY" # Get your key from app.easyparser.com
ASIN = "B098FKXT8L"
params = {
"api_key": API_KEY,
"platform": "AMZ",
"operation": "DETAIL",
"asin": ASIN,
"domain": ".com"
}
response = requests.get("https://realtime.easyparser.com/v1/request", params=params)
data = response.json()
product = data.get("product", {})
print(f"Title: {product.get('title')}")
print(f"Price: ${product.get('price')}")
print(f"Rating: {product.get('rating')} stars")
This approach eliminates the need to maintain complex infrastructure while guaranteeing access to the critical data required for competitive analysis and strategic decision-making.
Conclusion
The choice between web scraping vs api is no longer a strict binary. While DIY web scraping offers flexibility at the cost of high maintenance, and official APIs offer stability with restricted data access, the modern data extraction landscape favors hybrid solutions. For businesses that require reliable, large-scale data extraction without the engineering overhead, leveraging a specialized scraping API represents the most efficient and scalable path forward in 2026.
Start analyzing Amazon data for free
Start Your Free Trial100 free credits, no credit card required.