When you need to extract product data, monitor competitor pricing, or analyze market trends on the world's largest e-commerce platform, traditional web scraping methods simply no longer work. Amazon's sophisticated anti-bot systems, dynamic page structures, and aggressive rate limiting have made HTML parsing a relic of the past. To build reliable, scalable data pipelines in 2026, you need a dedicated Amazon scraping API.
This ultimate guide covers everything you need to know about extracting Amazon data at scale. We will explore the technical challenges of bypassing CAPTCHAs, compare the top API solutions available today, and demonstrate how to integrate real-time data into your applications. Whether you are an Amazon seller optimizing your pricing strategy or a developer building a competitive intelligence dashboard, this guide will provide the actionable insights you need.
Why Traditional Scraping Fails on Amazon
If you have ever tried to write a simple Python script using BeautifulSoup or Selenium to scrape Amazon, you have likely encountered the "Robot Check" page. Amazon employs one of the most advanced Web Application Firewalls (WAF) in the industry to protect its data. Here is why traditional methods fail:
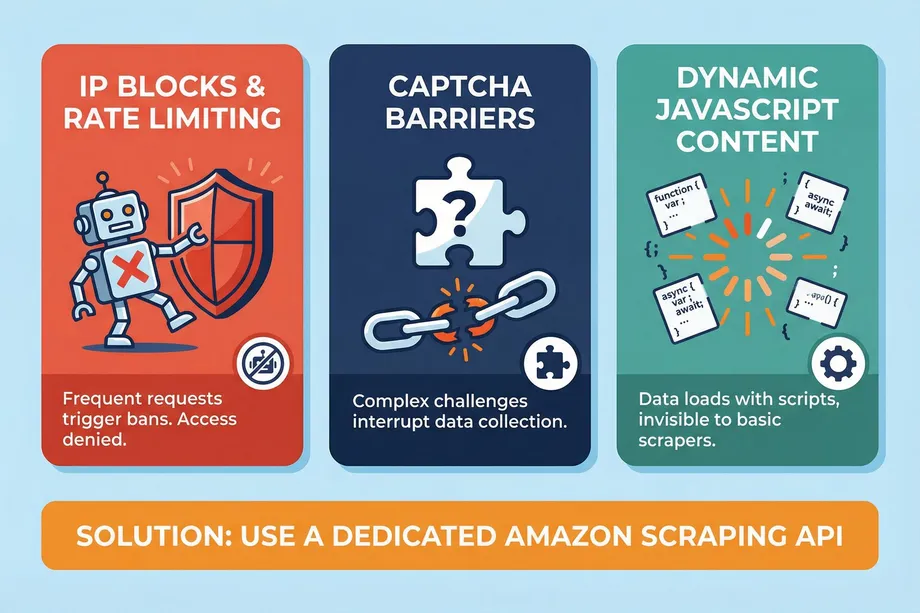
1. IP Blocks and Rate Limiting: Amazon monitors request frequency from individual IP addresses. If your script makes too many requests within a short window, your IP will be temporarily or permanently banned. Managing a massive pool of rotating residential proxies is expensive and technically complex.
2. CAPTCHA Barriers: When Amazon detects suspicious behavior, it serves a CAPTCHA. While there are automated CAPTCHA-solving services, they add latency and often fail against Amazon's constantly evolving challenges, breaking your automated data pipelines.
3. Dynamic JavaScript Content: Critical data points, such as real-time pricing, stock availability, and delivery estimates, are frequently loaded asynchronously via JavaScript. A simple HTTP GET request will only return the initial HTML shell, missing the actual data you need.
4. Geolocation Dependencies: Prices and shipping availability change based on the user's delivery address (ZIP code). Scraping from a server in Virginia will yield different results than a user browsing in California. To get accurate competitive data, your scraper must be able to simulate specific delivery locations.
What is an Amazon Scraping API?
An Amazon scraping API is a specialized service that handles all the underlying complexity of proxy management, browser rendering, and CAPTCHA solving on your behalf. Instead of downloading HTML and writing complex parsing logic, you simply send an HTTP request to the API with a product ASIN or search keyword, and the API returns clean, structured JSON data.
This abstraction allows developers to focus on building applications and analyzing data, rather than constantly updating XPath selectors when Amazon changes its page layout.
Core Use Cases for Amazon Data

Different teams utilize Amazon data for different strategic purposes. A robust Amazon scraping API must support the following core operations:
- Real-Time Price Monitoring: Sellers need to track competitor prices and Buy Box ownership minute-by-minute to adjust their own pricing dynamically.
- Product Research and Sales Analysis: Identifying winning products requires analyzing historical sales trends, Best Sellers Rank (BSR) fluctuations, and review velocity over time.
- Competitor Intelligence: Brands monitor search result rankings (organic vs. sponsored) to understand market share and optimize their SEO and PPC campaigns.
- Logistics and FBA Optimization: Sellers need accurate package dimensions and weight data to calculate Amazon FBA fulfillment fees and optimize their profit margins.
Comparing the Best Amazon Scraping APIs in 2026
The market is flooded with generic web scraping tools that claim to support Amazon. However, when evaluating an Amazon scraping API, you must distinguish between general-purpose proxy networks and purpose-built data extraction platforms.
| Feature | Easyparser | ScraperAPI | Oxylabs |
|---|---|---|---|
| Platform Focus | Dedicated Amazon API | General Web Scraping | Enterprise Proxy Network |
| Data Format | Structured JSON | Raw HTML (mostly) | Raw HTML / JSON |
| Sales History Data | ✅ Yes (12 months) | ⌠No | ⌠No |
| Package Dimensions | ✅ Yes | ⌠No | ⌠No |
| Pricing Model | 1 Credit = 1 Result | Complex multiplier | High monthly minimums |
Why Easyparser is the Superior Choice
While platforms like Oxylabs provide excellent proxy infrastructure, they are fundamentally generic tools. Easyparser is different; it is an API engineered exclusively for Amazon. This specialization provides three distinct advantages that generic scrapers cannot match:
1. Exclusive Data Endpoints: Easyparser provides access to data that is virtually impossible to extract via standard HTML scraping. The Sales Analysis & History operation delivers 12 months of historical data for price, BSR, and estimated views. The Package Dimension operation provides exact logistical data for FBA fee calculation features simply not found in competing APIs.
2. Transparent 1:1 Pricing: The industry standard is to advertise "100,000 credits" but charge 10 to 25 credits for a single Amazon request that requires JavaScript rendering or a premium proxy. Easyparser utilizes a strictly transparent model: 1 credit equals 1 successful product result. You never pay for failed requests.
3. Unmatched Speed: Because the infrastructure is optimized solely for Amazon's architecture, Easyparser's Real-Time API delivers structured JSON responses in approximately 7.5 seconds, making it ideal for live dashboards and dynamic repricing algorithms.
How to Integrate an Amazon Scraping API (Python Example)
Integrating Easyparser into your application is straightforward. The platform offers both a Real-Time API for instant, synchronous requests and a Bulk API for processing thousands of ASINs asynchronously via webhooks.
Here is an example of how to fetch detailed product information using Python and the `requests` library:
import requests
API_KEY = "YOUR_API_KEY" # Get your key from app.easyparser.com
ASIN = "B098FKXT8L"
params = {
"api_key": API_KEY,
"platform": "AMZ",
"operation": "DETAIL",
"asin": ASIN,
"domain": ".com"
}
response = requests.get("https://realtime.easyparser.com/v1/request", params=params)
data = response.json()
product = data.get("product", {})
print(f"Title: {product.get('title')}")
print(f"Price: ${product.get('price')}")
print(f"Rating: {product.get('rating')} stars")
For large-scale operations, such as updating your entire catalog's pricing daily, the Bulk API is the recommended approach. You submit a list of ASINs, and Easyparser processes them in parallel, sending the final JSON payload directly to your server via a webhook.
Real-Time API vs. Bulk API: Choosing the Right Approach
One of the most important architectural decisions when building an Amazon data pipeline is whether to use a synchronous Real-Time API or an asynchronous Bulk API. The right choice depends entirely on your use case and the volume of data you need to process.
The Real-Time API is designed for instant, on-demand requests. You send a request and receive a structured JSON response within seconds. This is the ideal choice for live applications such as repricing dashboards, product detail pages that need fresh data on each page load, or any workflow where a human or automated system is waiting for an immediate response. Easyparser's Real-Time API supports all available operations and responds in approximately 7.5 seconds.
The Bulk API, by contrast, is designed for high-volume, scheduled workloads. You submit a job containing up to 5,000 ASINs in a single request, and Easyparser processes them in parallel in the background. Instead of waiting for each response, you provide a webhook URL, and Easyparser sends the complete dataset to your server automatically when the job finishes. This approach is far more efficient for tasks like nightly catalog price updates, weekly competitor analysis across thousands of products, or building a historical database of BSR data.
| Criteria | Real-Time API | Bulk API |
|---|---|---|
| Response Type | Synchronous (instant) | Asynchronous (webhook) |
| Best For | Live dashboards, single lookups | Catalog updates, batch analysis |
| Max Items Per Request | 1 ASIN | Up to 5,000 ASINs |
| Latency | ~7.5 seconds | Minutes (parallel processing) |
A Deep Dive into Amazon API Operations
A truly useful Amazon scraping API is not a single endpoint that returns a generic product page dump. It is a suite of purpose-built operations, each designed to extract a specific type of data with maximum accuracy. Here is a breakdown of the key operations available through Easyparser and how each one serves a distinct business need.
DETAIL: The Foundation of Product Intelligence
The DETAIL operation is the most commonly used endpoint. It accepts an ASIN or a product URL and returns a comprehensive JSON object containing the product title, brand, all available images, current price, stock status, product variations (size, color), bullet points, and the full product description. This operation is the backbone of any product catalog enrichment or competitor monitoring system. You can explore the full list of supported operations on the Easyparser Amazon scraping API.
OFFER: Real-Time Competitive Pricing
The OFFER operation goes beyond the main product listing to retrieve all active third-party seller offers for a given ASIN. The response includes each seller's name, price, shipping cost, fulfillment method (FBA vs. FBM), and condition. This data is invaluable for Buy Box analysis, allowing sellers to understand exactly what price and fulfillment combination is required to win the featured offer position.
SALES ANALYSIS & HISTORY: The Competitive Edge
This is the operation that sets Easyparser apart from every other Amazon scraping API on the market. Rather than providing only a current snapshot, the SALES ANALYSIS & HISTORY endpoint returns up to 12 months of historical data for a given ASIN. This includes historical price changes, BSR fluctuations, review count growth, and estimated monthly views. For product researchers and investors, this data is transformative. It allows you to identify seasonal demand patterns, detect products that are trending upward before they become saturated, and perform due diligence on a product's long-term viability before launching a competing listing.
PACKAGE DIMENSION: Mastering FBA Profitability
Amazon FBA fees are calculated based on a product's size tier, which is determined by its dimensions and weight. An error in your fee calculation can turn a profitable product into a loss-maker. The PACKAGE DIMENSION operation returns the exact height, width, length, weight, and Amazon fee category for any ASIN. You can also access this data through the dedicated Easyparser Amazon scraping API. This allows developers to build automated FBA fee calculators that audit your entire catalog for fee discrepancies, which is a common source of hidden profit leakage for high-volume sellers.
SEARCH: Keyword and Category Monitoring
The SEARCH operation allows you to retrieve Amazon search result pages for any keyword, returning a list of products with their organic ranking position, sponsored status, ASIN, title, price, and rating. This is the core data source for keyword rank tracking tools, allowing brands to monitor their visibility for target keywords and measure the impact of their Amazon SEO efforts over time.
Node.js Integration Example
For teams working in a Node.js environment, integrating the Amazon scraping API is equally straightforward using the built-in `https` module or the popular `axios` library.
const axios = require('axios');
const params = {
api_key: 'YOUR_API_KEY',
platform: 'AMZ',
operation: 'OFFER',
asin: 'B098FKXT8L',
domain: '.com'
};
axios.get('https://realtime.easyparser.com/v1/request', { params })
.then(res => {
const offers = res.data.offers;
console.log(`Found ${offers.length} offers`);
console.log(`Lowest price: $${offers[0].price}`);
})
.catch(err => console.error(err.message));
The Legal Landscape of Scraping Amazon
When implementing an Amazon scraping API, it is crucial to understand the legal boundaries. The consensus, heavily influenced by the landmark hiQ Labs vs. LinkedIn ruling, is that scraping publicly available data (such as product prices, descriptions, and public reviews) is generally permissible and does not violate the Computer Fraud and Abuse Act (CFAA).
However, this protection only applies to public data. You must never attempt to scrape Personally Identifiable Information (PII) or data hidden behind a login wall. Using an API like Easyparser ensures you are only accessing the public-facing catalog, keeping your operations within ethical and legal data extraction boundaries.
Conclusion
Attempting to build and maintain an in-house Amazon scraper is a resource-intensive battle against CAPTCHAs, proxy bans, and constantly changing page layouts. By leveraging a dedicated Amazon scraping API, you can bypass these technical hurdles entirely and focus on what truly matters: analyzing the data to drive your business forward.
With its exclusive endpoints for historical sales data, transparent pricing model, and robust real-time performance, Easyparser stands out as the premier solution for Amazon data extraction in 2026. Explore all the Easyparser Amazon scraping API and streamline your data pipeline today.
Start building your Amazon data pipeline today
Start Your Free Trial100 free credits, no credit card required.


