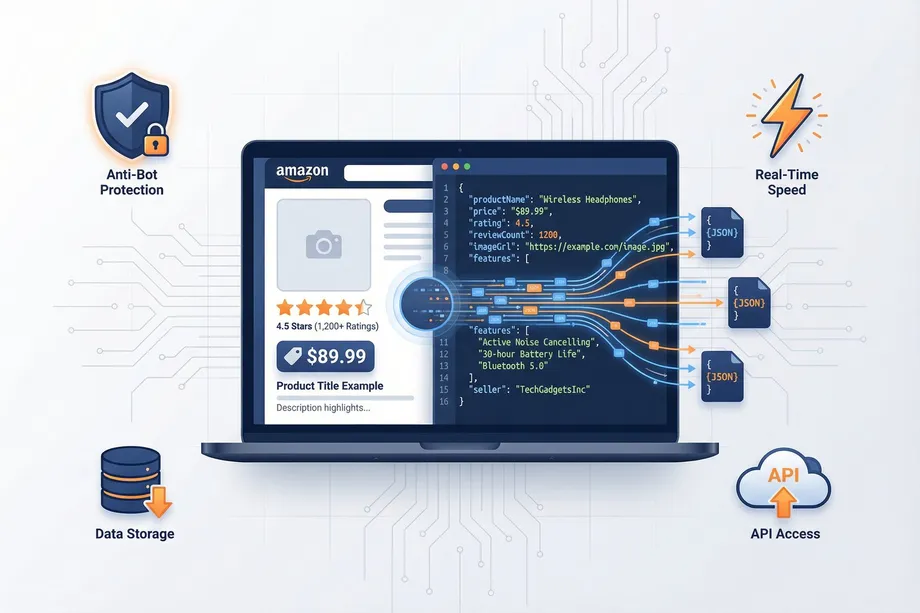
Every week, thousands of Amazon scrapers break. Selectors change, IPs get blocked, and data pipelines go silent. An Amazon scraping API eliminates this entirely by delivering structured JSON data without touching a single line of HTML. This guide will provide a deep dive into what an Amazon scraping API is, why it is fundamentally superior to traditional HTML scraping, and how a service like Easyparser plays a critical role in this process.
HTML Scraping vs. API: Why an API is the Superior Choice
When it comes to data extraction, there are two primary approaches: direct HTML scraping and using a dedicated API. Traditional HTML scraping involves parsing the HTML source code of a web page to extract data. While this method might seem simpler at first, it is unsustainable in the long run.
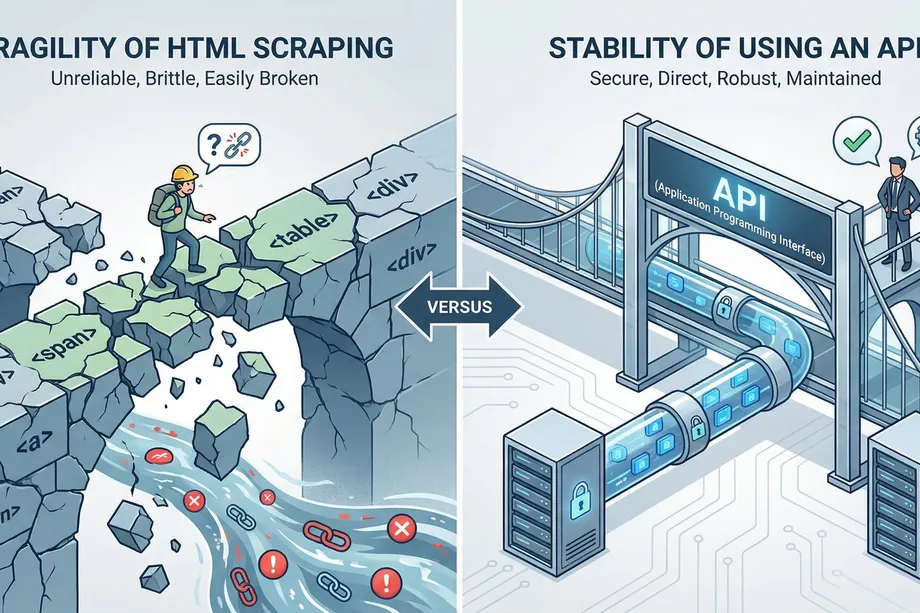
| Feature | HTML Scraping | API-based Data Extraction |
|---|---|---|
| Reliability | Brittle; breaks with the slightest change in Amazon's layout. | Resilient; the API provider manages all infrastructure changes. |
| Maintenance | Requires constant code updates and maintenance. | Zero maintenance required; managed entirely by the provider. |
| Block Risk | High; frequently encounters IP blocks, CAPTCHAs, and other anti-bot measures. | Low; the API uses advanced techniques to bypass blocks reliably. |
| Speed & Scale | Slow and difficult to scale for high-volume requests. | Fast, concurrent, and built to handle high-volume requests. |
| Data Quality | Delivers messy, unstructured, and inconsistent data. | Provides clean, structured, and ready-to-use JSON data. |
| Customization & Edge Cases | Highly flexible; you can target any data element and handle niche edge cases with fully custom logic. | Limited to what the provider exposes; niche edge cases may not be supported out of the box. |
In short, while HTML scraping might be a solution for short-term, small-scale projects, using an Amazon scraping API is the only logical path for a reliable, scalable, and long-term data strategy. It allows you to focus on leveraging data, not on the fragile mechanics of acquiring it.
Core Use Cases for an Amazon Scraping API
The power of an Amazon scraping API is most evident when applied to solve real-world business problems.
1. Dynamic Price Tracking and Repricing
By monitoring competitors' prices in real-time, you can automatically adjust your own pricing to win the "Buy Box" and maximize your profit margins. The low latency of an API like Easyparser ensures you can react to market changes instantly. Brands using real-time repricing see an average 15–30% increase in Buy Box win rate.
2. Competitor and Market Analysis
Gather comprehensive data on competitor products, stock levels, customer reviews, and pricing strategies. Use a `Search` operation to discover new entrants in your niche and analyze their performance over time.
3. Inventory and Availability Monitoring
Optimize your inventory and supply chain decisions by tracking whether a product is in stock or when it is likely to be restocked. This is especially vital for retail arbitrage and dropshipping business models.
Technical Deep Dive: Architecting a Reliable Data Pipeline
When scraping data at scale (e.g., 10,000+ ASINs), building a reliable infrastructure is paramount. This typically requires a data pipeline architecture that includes the following components:
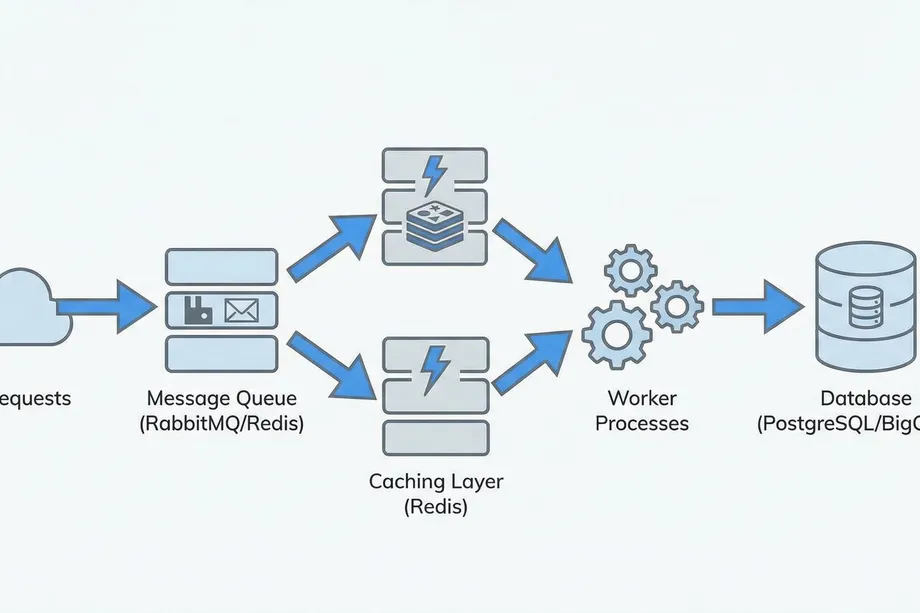
- Queue-based Ingestion: A message queue system like RabbitMQ or Redis is used to manage a high volume of requests. This prevents request loss and helps you adhere to API rate limits.
- Caching Layer: Storing frequently requested data in a cache like Redis significantly reduces API costs and improves response times.
- Data Storage: The extracted structured data is stored in a database like PostgreSQL or BigQuery for analysis and long-term retention.
- Retry Strategy: API requests can occasionally fail due to network issues or temporary blocks. Implementing a smart retry strategy, such as exponential backoff, prevents data loss.
Using a managed Amazon scraping API like Easyparser handles this complex infrastructure for you, allowing you to focus directly on data analysis.
Extracting Amazon Data with Easyparser: Code Examples
Easyparser offers a simple and powerful interface designed for developers. Here are examples of how to retrieve product details using Python and Node.js.
Python Example
import requests
import json
API_KEY = "YOUR_API_KEY" # Get your key from app.easyparser.com
ASIN = "B09V323255" # Example ASIN
params = {
"api_key": API_KEY,
"platform": "AMZ",
"operation": "DETAIL",
"asin": ASIN,
"domain": ".com"
}
api_result = requests.get("https://realtime.easyparser.com/v1/request", params=params)
if api_result.status_code != 200:
print(f"Error: {api_result.status_code}")
else:
product_data = api_result.json()
print(json.dumps(product_data, indent=2))
Node.js Example
const axios = require('axios');
const API_KEY = 'YOUR_API_KEY'; // Get your key from app.easyparser.com
const ASIN = 'B09V323255'; // Example ASIN
const params = {
api_key: API_KEY,
platform: 'AMZ',
operation: 'DETAIL',
asin: ASIN,
domain: '.com'
};
axios.get('https://realtime.easyparser.com/v1/request', { params })
.then(response => {
console.log(JSON.stringify(response.data, null, 2));
})
.catch(error => {
const status = error.response ? error.response.status : 'unknown';
console.error(`Request failed with status ${status}. Retrying...`);
});
Next Steps
- Sign up for free 100 requests/month, no credit card required.
- Try with your first ASIN paste any Amazon product ID and run your first API call.
- See results in under 30 seconds get clean, structured JSON data ready to use in your pipeline.
Start Making Data-Driven Decisions Today
Stop guessing and start analyzing. Get access to sales history, traffic data, and logistics intelligence that competitors simply cannot provide. Try the Easyparser API suite and discover profitable opportunities with confidence.
Start extracting Amazon data for free
Start Your Free Trial100 free credits, no credit card required.