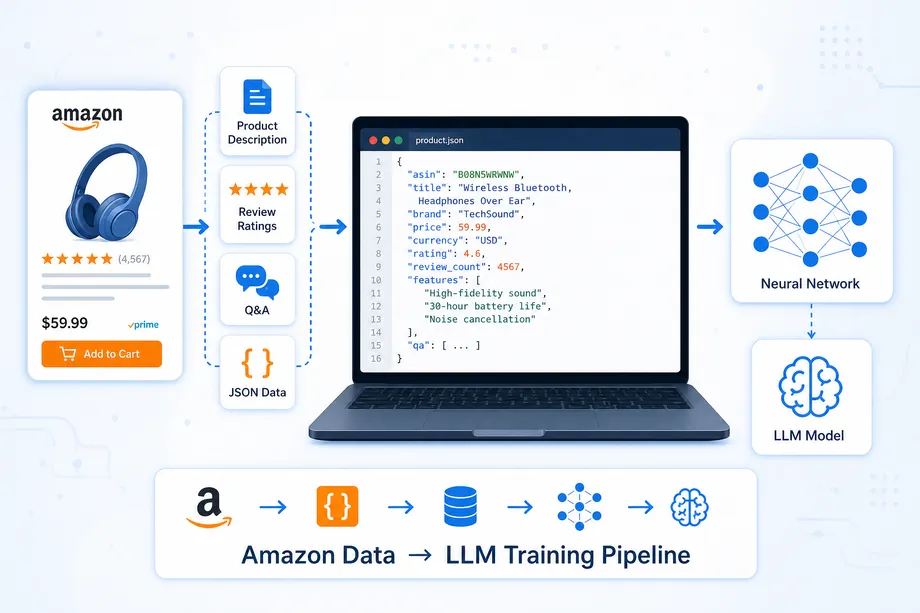
The landscape of web scraping has fundamentally changed. In the past, data extraction was synonymous with writing brittle CSS selectors, maintaining complex parsing scripts, and spending hours fixing pipelines every time a target website updated its layout. Today, the integration of ai agents web scraping technologies has transformed this tedious process into a resilient, autonomous workflow. By combining reliable data extraction APIs with Large Language Models (LLMs), modern developers are building intelligent data pipelines that not only extract raw information but analyze it and generate actionable insights automatically.
This shift from manual parsing to LLM-powered extraction represents a massive leap in efficiency. Instead of telling a script exactly where to find a price on an Amazon page, you simply provide the raw HTML or JSON and ask the AI agent to "extract the product price, title, and rating." The agent understands the context, adapts to structural changes, and returns clean, structured data. This guide will walk you through the process of building these intelligent data pipelines, focusing on the powerful combination of the OpenAI API and robust extraction tools like Easyparser.
What Are AI Agents for Web Scraping?
At their core, AI agents in the context of web scraping are software programs that use LLMs to navigate, interpret, and extract information from web content autonomously. Unlike traditional scrapers that follow rigid, hard-coded instructions, AI agents can "read" a page much like a human would. They understand the semantic meaning of the content, allowing them to identify the main product description, the pricing tiers, or the customer reviews, regardless of how the underlying HTML is structured.
When we talk about ai agents web scraping, we are usually referring to a two-stage process. The first stage involves acquiring the raw data from the web. This is where tools like Easyparser excel, handling the complexities of proxy management, CAPTCHA solving, and reliable HTML/JSON retrieval. The second stage involves passing this raw data to an LLM, such as OpenAI's GPT-4, which acts as the intelligent parsing engine. The LLM extracts the desired fields and formats them according to a strict schema, ensuring the output is ready for immediate use in databases or applications.
LLM vs Traditional Scraping: What Actually Changes
The transition to LLM-powered scraping eliminates some of the most frustrating aspects of data extraction while introducing new considerations regarding cost and performance. Let's examine the key differences between the two approaches.
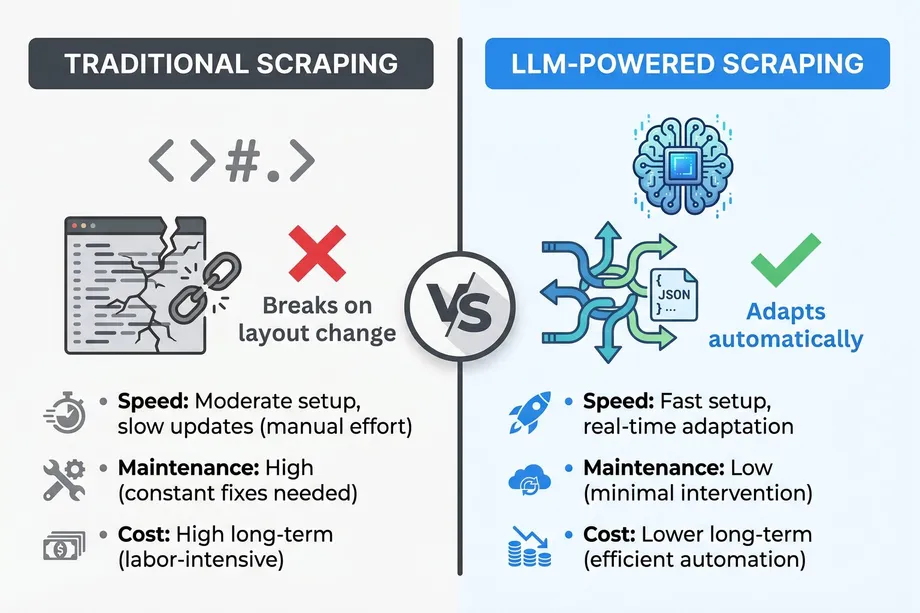
Maintenance and Resilience: Traditional scrapers rely heavily on XPath or CSS selectors. If an e-commerce site changes its class names from .product-price-large to .price-tag-new, the scraper breaks immediately, requiring developer intervention. LLMs, however, look at the content itself. Even if the entire DOM structure changes, the LLM can still identify the text "$49.99" next to "Price" and extract it correctly. This resilience dramatically reduces maintenance overhead.
Setup Speed: Writing a traditional scraper requires inspecting the DOM, testing selectors, and writing custom parsing logic for each target website. With LLMs, the setup is often as simple as writing a natural language prompt describing the data you want and defining the expected JSON output structure. This allows developers to scale their scraping operations across hundreds of different websites much faster.
Cost Structure: This is where the trade-offs become apparent. Traditional scraping is computationally cheap once built; running a CSS selector costs virtually nothing. LLM extraction, however, incurs a per-token cost for every page processed. For high-volume, highly standardized scraping (like pulling millions of Amazon products daily), dedicated APIs with structured JSON responses are more cost-effective. But for complex, unstructured data, or when scraping thousands of disparate sites, the engineering time saved by using LLMs often outweighs the token costs.
How to Connect OpenAI API with a Web Scraping API
To build an intelligent data pipeline, you need to connect your data source to your AI agent. The most robust way to do this is by using a reliable web scraping API to fetch the raw content, and then passing that content to the OpenAI API for structured extraction.
For Amazon data, Easyparser provides the perfect first stage. Rather than dealing with raw HTML, Easyparser's Amazon Product Detail API returns clean, structured JSON. You can then use the OpenAI API to analyze this data, summarize reviews, or generate product descriptions.
Here is an example of how you might fetch data using Easyparser and then pass it to OpenAI for analysis:
import requests
import json
from openai import OpenAI
# 1. Fetch data using Easyparser
ep_params = {
"api_key": "YOUR_EASYPARSER_KEY",
"platform": "AMZ",
"operation": "DETAIL",
"domain": ".com",
"asin": "B0CJB6V2L5"
}
ep_response = requests.get("https://realtime.easyparser.com/v1/request", params=ep_params)
product_data = ep_response.json()
# 2. Analyze data with OpenAI
client = OpenAI(api_key="YOUR_OPENAI_KEY")
prompt = f"Analyze this Amazon product data and write a 2-sentence marketing summary highlighting its key features: {json.dumps(product_data.get('product', {}))}"
ai_response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}]
)
print(ai_response.choices[0].message.content)
Building an Intelligent Data Pipeline: Step-by-Step
Creating a robust pipeline involves more than just a simple script. An intelligent data pipeline using ai agents web scraping must handle data acquisition, structured extraction, and automated reporting seamlessly.
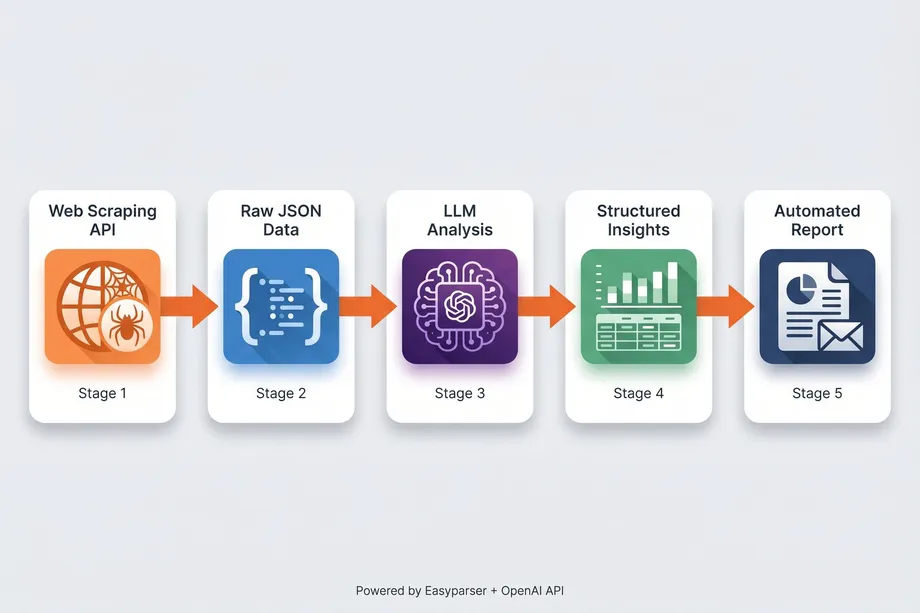
Stage 1: Reliable Data Acquisition. The foundation of any pipeline is getting the data without being blocked. Attempting to build your own proxy rotation and anti-bot bypass systems is a massive drain on engineering resources. Using a dedicated service ensures you receive the raw HTML or JSON consistently. For Amazon-specific pipelines, Easyparser's Real-Time API handles all the heavy lifting, delivering data in ~7.5 seconds.
Stage 2: Structured Output Definition. Before passing data to an LLM, you must define exactly what you want back. OpenAI's Structured Outputs feature (using JSON Schema) guarantees that the model will return data matching your exact specifications. If you need a product title, a float value for the price, and a boolean for Prime eligibility, you define this schema, and the LLM adheres to it strictly.
Stage 3: LLM Extraction and Analysis. In this stage, the AI agent processes the raw content. If you are scraping unstructured news articles, the LLM extracts the entities based on your schema. If you are using Easyparser, which already provides structured JSON, the LLM can be used for higher-order analysis, such as sentiment analysis on reviews or categorizing products based on their descriptions.
Automating Reports: LLM Analysis of Extracted Data
The true power of ai agents web scraping is realized when extraction is combined with automated analysis. Instead of simply dumping data into a database for a human analyst to review later, the AI agent can generate insights immediately.
Consider an e-commerce competitor analysis pipeline. The system can be scheduled to run daily, using Easyparser's Sales Analysis API to track price history and trends for hundreds of competitor products. Once the data is retrieved, an AI agent can analyze the price changes, cross-reference current Best Sellers Rank positions by category, identify new product variations, and summarize the overall market movement. The final output is not a massive spreadsheet, but a concise, automated report emailed directly to the pricing team, highlighting only the actionable insights.
This level of automation transforms data extraction from a technical hurdle into a strategic advantage, allowing teams to react to market changes faster than ever before.
Cost Optimization: When to Use LLM Extraction vs Selectors
While LLMs offer incredible flexibility, they are not always the right tool for every job. Cost optimization is a critical factor when designing data pipelines at scale.
If you are scraping a single, highly structured website (like Amazon) for millions of records, using an LLM to parse every page is prohibitively expensive and unnecessary. In these scenarios, dedicated APIs that use optimized, hard-coded extraction logic are far superior. For example, Easyparser's Search Listing API returns hundreds of keyword-matched products in a single call, while the Product Offer API delivers real-time pricing from all sellers both at a fraction of the cost of LLM token usage. When your pipeline receives products identified by barcodes, UPCs, or EANs rather than ASINs, the Product Lookup API resolves these identifiers to their corresponding Amazon ASINs in a single step, enabling seamless catalog enrichment without manual cross-referencing. Easyparser's 1:1 credit model provides predictable, low-cost extraction for these exact use cases.
Conversely, if you need to extract specific data points from 5,000 different, uniquely structured websites (e.g., extracting contact information from various company "About Us" pages), writing 5,000 different CSS selectors is impossible. Here, ai agents web scraping shines. The token cost of the LLM is negligible compared to the engineering hours required to build and maintain thousands of custom scrapers.
Real-World Use Case: Amazon Data + OpenAI Integration
Let's look at a practical application combining Easyparser and OpenAI for advanced Amazon seller intelligence. A seller wants to monitor a competitor's product and automatically generate a summary of recent negative reviews to identify product flaws they can capitalize on.
The pipeline would use Easyparser to fetch the product details and reviews. For broader competitive intelligence, the Seller Profile API can also reveal the competitor's overall performance metrics and feedback history. Because Easyparser handles the complex Amazon anti-bot systems, the data retrieval is reliable. The pipeline then feeds the review text into the OpenAI API with a prompt like: "Analyze these recent 1-star and 2-star reviews. Identify the three most common complaints and summarize them in bullet points."
This workflow leverages the strengths of both tools: Easyparser provides the reliable, structured data acquisition, and the AI agent provides the nuanced, semantic analysis that traditional scripts cannot achieve. This is the future of data pipelines intelligent, automated, and highly actionable.
Conclusion
The era of brittle, high-maintenance web scrapers is ending. By embracing ai agents web scraping, developers and data teams can build resilient, intelligent data pipelines that adapt to change and provide deeper insights. While LLMs offer unprecedented flexibility for parsing unstructured web content, they are best utilized in conjunction with robust data acquisition tools. For specialized tasks like Amazon data extraction, combining a dedicated service like Easyparser with the analytical power of AI agents creates a workflow that is both highly reliable and profoundly intelligent, allowing businesses to focus on acting on data rather than fighting to extract it.
Start extracting Amazon data for free
Start Your Free Trial100 free credits, no credit card required.