In today's hyper-competitive online retail landscape, relying on intuition is no longer sufficient. To succeed, businesses need actionable intelligence, and that begins with mastering ecommerce data extraction. This guide serves as your comprehensive 101 resource, breaking down the essential methods, tools, and best practices required to collect product, pricing, and review data at scale in 2026. Whether you are a developer building a data pipeline, a seller tracking competitor prices, or an analyst building market models, understanding the full scope of ecommerce data extraction is the first step toward a sustainable competitive advantage.
What Is E-Commerce Data Collection?
At its core, e-commerce data collection is the automated process of retrieving structured information from online retail platforms. It transforms raw web pages into structured datasets (like JSON or CSV) that can be analyzed to drive business decisions. Whether you are tracking competitor pricing, monitoring inventory levels, or analyzing customer sentiment through reviews, robust data collection forms the foundation of modern retail intelligence.
The global e-commerce market is projected to reach $6.88 trillion in 2026, and the volume of publicly available product data is growing at the same pace. Businesses that can efficiently capture and process this data gain a measurable edge over those that cannot. Ecommerce data extraction is no longer a niche technical skill; it is a core operational capability for any data-driven retail business.
Types of E-Commerce Data You Can Collect
The scope of ecommerce data extraction is vast. Here are the primary categories of data that businesses typically target:
- Product Catalog Data: Titles, descriptions, specifications, high-resolution images, and variant details (size, color, material).
- Pricing and Availability: Real-time price tracking, discount history, coupon data, and stock status across different regions and fulfillment types.
- Customer Sentiment: Reviews, ratings, Q&A sections, and verified purchase flags that provide deep insights into consumer preferences and product quality.
- Seller Metrics: Buy Box ownership, seller ratings, shipping performance, and feedback scores.
- Market Demand Signals: Best Sellers Rank (BSR), "Bought in Past Month" counts, and search ranking positions that indicate product velocity and demand trends.
For buyers, this data enables smarter purchasing decisions and price comparison. For sellers, it is the raw material for competitive intelligence, dynamic pricing strategies, and product development. Both sides of the marketplace benefit from reliable, structured data.
Data Sources: Amazon, Walmart, and Other Marketplaces
Different platforms present unique challenges and opportunities for ecommerce data extraction. Amazon, as the undisputed giant with over 300 million product listings, offers the richest data but deploys aggressive anti-bot measures. In 2026, Amazon's defenses include TLS fingerprinting, HTTP/2 frame analysis, browser fingerprinting, and behavioral profiling. Any DIY scraper that fails to account for these layers will face IP bans and CAPTCHA walls within hours.
Walmart is rapidly growing its marketplace and requires localized extraction strategies, particularly for geo-accurate pricing data that varies by ZIP code. Other platforms like Shopify stores, eBay, and regional marketplaces may have simpler structures but still require reliable extraction pipelines to ensure data freshness and consistency.
The key insight is that no single extraction strategy works across all platforms. A robust ecommerce data extraction architecture must be flexible enough to handle platform-specific quirks while maintaining a consistent output schema for downstream analysis.
Manual vs API-Based Extraction: Speed, Scale, and Cost Compared
When starting with ecommerce data extraction, the initial instinct is often to build a custom, manual scraper using Python libraries like BeautifulSoup or Selenium. While this offers flexibility, it quickly becomes a maintenance burden. Marketplaces frequently update their layouts, instantly breaking custom scripts and requiring urgent developer intervention. The hidden costs of proxy management, server infrastructure, and developer hours dedicated to fixing broken scrapers often outweigh the perceived benefits of a "free" DIY solution.
Conversely, API-based extraction provides structured, reliable data access. As highlighted in our comparison of Web Scraping vs API, an API abstracts the complexities of proxy management and layout changes, allowing your team to focus on analysis rather than maintenance. The table below summarizes the key trade-offs:
| Criteria | Manual Scraping | API-Based Extraction |
|---|---|---|
| Setup Time | Days to weeks | Hours |
| Maintenance | High (breaks on layout changes) | Low (provider handles updates) |
| Scale | Limited by proxy infrastructure | Scales to millions of requests |
| Data Structure | Inconsistent HTML parsing | Consistent, structured JSON |
| Anti-Bot Handling | Manual, fragile | Built-in, automatic |
| Cost at Scale | High (infrastructure + dev time) | Predictable, usage-based |
Web Scraping APIs: The Modern Standard for Ecommerce Data Extraction
To overcome the limitations of manual scraping, modern businesses turn to dedicated Web Scraping APIs. These services act as an intermediary, handling CAPTCHAs, IP rotation, and dynamic content rendering. For platforms with notoriously difficult anti-bot measures, a specialized scraping API is often the only viable solution to ensure continuous, uninterrupted data flow.
Easyparser operates precisely on this model. As a dedicated Amazon data extraction API, it resolves the core conflicts of the scraping vs. API debate. By providing endpoints for operations like Product Detail, Product Offer, Sales Analysis and History, and Best Sellers Rank, Easyparser delivers the depth of scraped data with the speed and reliability of an enterprise API. This makes it the ideal backbone for any serious ecommerce data extraction pipeline.
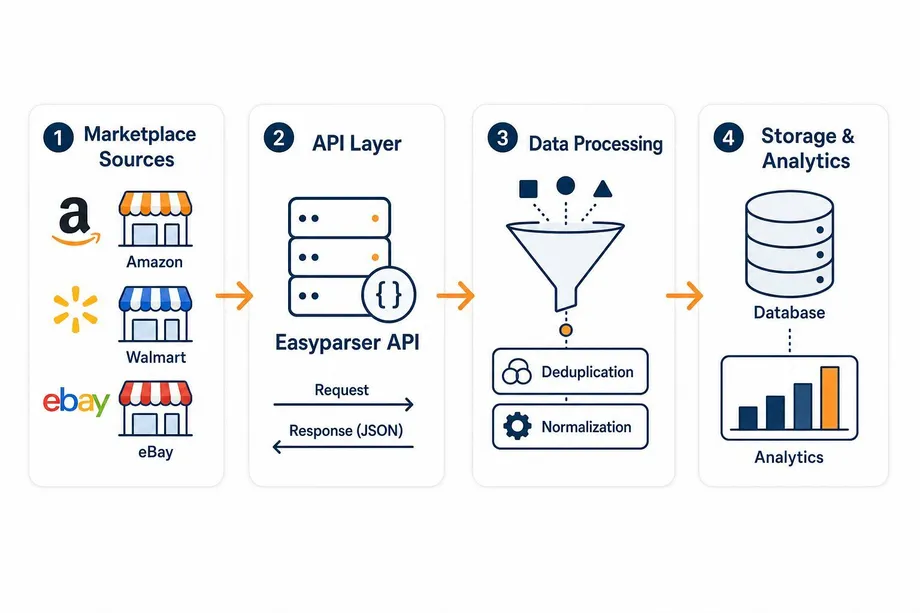
Building Your First E-Commerce Data Pipeline
Constructing a scalable data pipeline requires a strategic approach. A well-designed ecommerce data extraction pipeline consists of four core stages: ingestion, processing, storage, and analysis. Getting each stage right ensures that data flows reliably from raw marketplace pages to actionable business insights.
- Ingestion: Use a robust API to fetch raw data efficiently. For Amazon, the Easyparser API provides both Real-Time (synchronous, ~7.5s response) and Bulk (asynchronous, webhook-based) modes, giving you flexibility based on your use case.
- Processing and Normalization: Clean and standardize the incoming JSON data to ensure consistency across different sources. This includes handling missing fields, normalizing price formats, and standardizing category taxonomies.
- Storage: Load the processed data into a data warehouse or database (e.g., PostgreSQL, Snowflake, BigQuery) for long-term storage and historical trend analysis.
- Analysis and Visualization: Connect BI tools (like Tableau or PowerBI) or build custom dashboards to generate actionable insights from your extracted data.
Here is a Python example demonstrating how to integrate the Easyparser API into your pipeline for real-time ecommerce data extraction:
import requests
API_KEY = "YOUR_API_KEY" # Get your key from app.easyparser.com
ASIN = "B098FKXT8L"
params = {
"api_key": API_KEY,
"platform": "AMZ",
"operation": "DETAIL",
"asin": ASIN,
"domain": ".com"
}
response = requests.get("https://realtime.easyparser.com/v1/request", params=params)
data = response.json()
product = data.get("product", {})
print(f"Title: {product.get('title')}")
print(f"Price: ${product.get('price')}")
print(f"Rating: {product.get('rating')} stars")
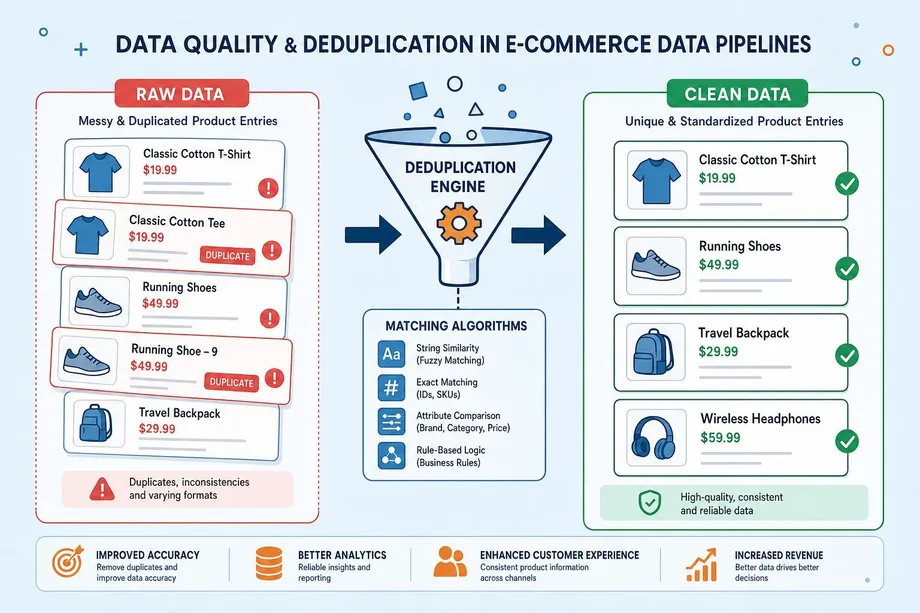
Data Quality: Handling Missing and Inconsistent Data
Data quality is paramount in any ecommerce data extraction project. When collecting data across multiple regions and platforms, inconsistencies are inevitable. Product titles may vary slightly between regions, prices may be missing for out-of-stock items, and the same product may appear under different ASINs or SKUs across different marketplaces.
Implementing robust deduplication strategies and validation checks ensures that your analytical models are built on accurate, reliable information. Key practices include: using unique identifiers (like ASINs) as primary keys, implementing fuzzy matching algorithms to detect near-duplicate product entries, setting automated alerts for missing critical fields (like price or stock status), and scheduling regular data quality audits to catch systematic issues early.
Use Cases: Pricing, Research and Competitive Intelligence
The applications for ecommerce data extraction are extensive and directly impact business outcomes across the retail value chain. Here are the most impactful use cases in 2026:
Dynamic Pricing and Buy Box Optimization: Sellers use real-time price data from the Product Offer API to monitor competitor pricing and adjust their own prices dynamically. Winning the Buy Box on Amazon can increase sales by 80% or more, making real-time offer data one of the highest-ROI data sources available.
Market Research and Demand Forecasting: Analysts extract historical BSR data and sales velocity signals to identify emerging product trends before they peak. This allows brands and private label sellers to make inventory decisions weeks ahead of demand spikes, reducing both stockouts and overstock situations.
Competitive Intelligence: Brands monitor competitor listings, pricing strategies, and customer reviews to identify gaps in their own product lines. Negative review analysis, in particular, is a goldmine for product development teams looking to build better versions of existing products.
Catalog Enrichment: Retailers and distributors use extracted product data to enrich their own catalogs with accurate specifications, high-resolution images, and standardized category hierarchies, reducing the manual data entry burden on their teams.
Compliance and Ethical Data Collection Practices
As data privacy regulations tighten globally, ethical ecommerce data extraction is non-negotiable. Businesses must ensure compliance with regional laws such as GDPR in Europe and CCPA in the United States by avoiding the extraction of Personally Identifiable Information (PII) and respecting platform terms of service where applicable.
The 2024 Meta v. Bright Data court precedent established that extracting publicly available data is generally permissible, but the legal landscape continues to evolve. Partnering with compliant API providers like Easyparser mitigates legal risks significantly, as the provider maintains the necessary infrastructure and compliance frameworks on your behalf. This allows your team to focus on building data products without navigating complex legal terrain independently.
In summary, mastering ecommerce data extraction in 2026 requires a combination of the right tools, a well-designed pipeline architecture, and a commitment to data quality and compliance. By leveraging modern API-based extraction solutions, businesses can access the rich data available across major marketplaces reliably and at scale, turning raw product data into the competitive intelligence that drives growth.
Start extracting Amazon data for free
Start Your Free Trial100 free credits, no credit card required.