
When evaluating web scraping solutions for e-commerce, the choice often comes down to versatility versus specialization. For developers and businesses extracting data from Amazon, comparing easyparser vs scrape.do highlights this fundamental divergence. Scrape.do has established itself as a robust, general-purpose proxy API capable of handling anti-bot measures across the web. However, as Amazon data requirements become increasingly complex, many users are discovering the limitations of generic scraping tools. This comprehensive guide compares Easyparser and Scrape.do across pricing, performance, and Amazon-specific capabilities to determine which API truly wins for Amazon data extraction in 2026.
Easyparser vs Scrape.do: Feature Comparison
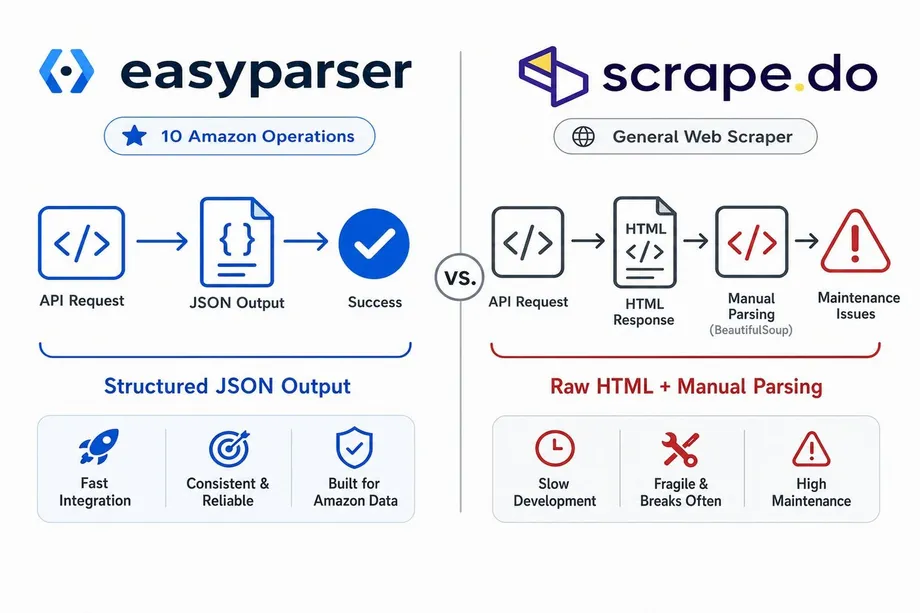
To understand the core differences in the easyparser vs scrape.do debate, one must look at their architectural focus. Scrape.do operates primarily as an intelligent proxy layer. It rotates IPs, handles CAPTCHAs, and renders JavaScript, but its final output is the raw HTML of the target page. This means that if you use Scrape.do for Amazon scraping, you are still responsible for writing, maintaining, and updating the parsing logic (often using libraries like BeautifulSoup) every time Amazon changes its page structure.
Conversely, Easyparser is a specialized Amazon Data API. It does not just bypass Amazon's Web Application Firewall (WAF); it completely abstracts the parsing layer. When you request a product via Easyparser, you receive a clean, structured JSON response containing exact data points like ASIN, title, variations, and high-resolution images. This specialization extends to ten dedicated Amazon operations, including Product Detail, Product Offers, and Search Listings, eliminating the need for any in-house parsing infrastructure.
Pricing Models: How Each API Charges
Pricing transparency is a critical factor for scaling data operations. Scrape.do offers a seemingly low entry point with a $29/month Hobby plan that provides 250,000 API credits. However, their credit consumption model is highly variable. A basic datacenter request costs 1 credit, but if you need a residential proxy with JavaScript rendering to bypass strict anti-bot measures, a single request can cost up to 25 credits. This variability makes cost forecasting difficult for large-scale Amazon scraping projects.
Easyparser champions a transparent 1:1 credit model. One credit equals one successful product result, with no hidden multipliers for residential proxies or complex rendering. The Beginner plan starts at $49/month for 100,000 credits ($0.49 per 1,000 results), while the Starter plan offers 350,000 credits for $150/month ($0.43 per 1,000 results). When evaluating easyparser vs scrape.do pricing for Amazon specifically, Easyparser's predictable model often proves significantly more cost-effective, especially when extracting complex variant data that would require expensive rendering on generic platforms.
Amazon-Specific Capabilities: Product, Offers & Reviews
The true test of an Amazon scraper is its ability to handle deep e-commerce metrics. Scrape.do is excellent at retrieving the HTML of a standard product page. However, Amazon sellers and analysts require more than just the main title and price. They need comprehensive Buy Box analysis, shipping dimensions, and historical sales data.
This is where Easyparser demonstrates its specialized advantage. Easyparser offers exclusive endpoints that are simply unavailable through a generic proxy API. For instance, the Sales Analytics API provides historical sales performance and BSR trends, which are crucial for product research. The Package Dimensions API delivers exact shipping weights and fulfillment sizes, allowing FBA sellers to audit fees accurately. Furthermore, the Product Offers API instantly returns structured data on all competing sellers, including their fulfillment methods (FBA/FBM) and Buy Box status, without requiring any custom HTML parsing.

Success Rate Benchmark: Scrape.do vs Easyparser
Both platforms boast impressive success rates, generally exceeding 98%. Scrape.do achieves this through a massive pool of over 110 million datacenter, residential, and mobile proxies across 150 countries. They act as an intelligent proxy layer, managing the TLS fingerprints and HTTP headers required to bypass systems like Cloudflare and AWS WAF.
Easyparser achieves its high success rate through deep optimization specifically for Amazon's anti-bot architecture. Because Easyparser focuses solely on Amazon, its proxy rotation and retry mechanisms are tuned precisely to Amazon's rate-limiting behaviors. Furthermore, Easyparser only deducts credits for successful operations. If an extraction fails, you are not charged, ensuring that your budget is spent entirely on usable data rather than blocked requests.
Response Time: Real-Time API Performance
Response time is a critical metric, particularly for dynamic repricing or live inventory monitoring. Scrape.do advertises a fast gateway, but when targeting Amazon, the latency depends heavily on the type of proxy required and whether JavaScript rendering is enabled. Third-party benchmarks have sometimes placed generic scrapers in the 10-15 second range for complex Amazon pages.
Easyparser offers two distinct integration methods to optimize response times. The Real-Time API is engineered for synchronous operations, delivering fully structured JSON responses in approximately 7.5 seconds. For high-volume tasks, Easyparser provides a Bulk API. This asynchronous method allows you to submit large batches of ASINs, which are processed efficiently in the background and delivered via webhook. This dual approach ensures that whether you need immediate data for a user interface or high-throughput processing for catalog updates, the API performs optimally.
Data Output Format: JSON Quality Comparison
The difference in data output format is perhaps the most significant operational distinction in the easyparser vs scrape.do comparison. With Scrape.do, your output is the raw HTML of the Amazon page. You must maintain Python scripts using BeautifulSoup or similar libraries to locate the specific CSS classes for prices, titles, and reviews. When Amazon inevitably updates its DOM structure, your parsing scripts will break, requiring immediate developer intervention.
Easyparser completely eliminates this maintenance burden. The output is a highly structured, predictable JSON object. Whether you are extracting a single product or a complex listing with dozens of color and size variations, the JSON schema remains consistent. This allows your engineering team to focus on building features and analyzing data, rather than constantly repairing broken parsing logic.
Here is an example of how simple it is to retrieve structured data using Easyparser's Real-Time API with Python:
import requests
API_KEY = "YOUR_API_KEY" # Get your key from app.easyparser.com
ASIN = "B0CJB6V2L5"
params = {
"api_key": API_KEY,
"platform": "AMZ",
"operation": "DETAIL",
"asin": ASIN,
"domain": "com"
}
response = requests.get("https://realtime.easyparser.com/v1/request", params=params)
data = response.json()
product = data.get("product", {})
print(f"Title: {product.get('title')}")
print(f"Price: ${product.get('price')}")
print(f"Rating: {product.get('rating')} stars")
Proxy and Anti-Bot Infrastructure
Scrape.do relies on a massive, generalized proxy network. They act as a middleman, upgrading your request to mimic legitimate browser behavior at multiple layers (TLS, HTTP, JavaScript) before routing it through their IP pool. This is highly effective for general web scraping across thousands of different domains.
Easyparser's infrastructure is hyper-focused. Instead of maintaining rules for every website on the internet, Easyparser's anti-bot mechanisms are dedicated solely to understanding and bypassing Amazon's specific AWS WAF and CAPTCHA systems. This includes sophisticated ZIP-code level geo-targeting, which is essential for extracting accurate, localized pricing and shipping availability on Amazon. While Scrape.do offers geo-targeting, Easyparser's implementation is natively integrated into its Amazon operations, ensuring that the data reflects exactly what a local buyer would see.
Developer Documentation and Support
Both platforms offer extensive documentation. Scrape.do provides clear instructions on how to format requests, handle cookies, and utilize their API playground. They emphasize their customer support, offering direct access to engineers without a ticketing system.
Easyparser's documentation is tailored for e-commerce developers. It provides detailed schemas for every Amazon operation, explaining exactly what data points will be returned for a Product Detail request versus a Search Listing request. Furthermore, Easyparser's support team consists of experts who understand the nuances of Amazon data, providing guidance not just on API integration, but on the best strategies for extracting specific e-commerce metrics like Buy Box ownership or variant mapping. You can explore all available operations on the Amazon Scraping API page.
Final Verdict: Which API Wins for Amazon Data?
The conclusion of the easyparser vs scrape.do comparison depends entirely on your use case. If you are building a generalized data extraction tool that needs to scrape thousands of different websites, Scrape.do is an excellent, powerful proxy solution.
However, if your primary focus is Amazon, Easyparser is the definitive winner. By providing structured JSON output, a transparent 1:1 pricing model, and exclusive endpoints for Sales History and Package Dimensions, Easyparser eliminates the massive overhead of maintaining custom parsing scripts. It transforms a complex web scraping task into a simple, reliable API integration, allowing your business to focus on leveraging data rather than fighting to extract it.
Start monitoring your competitors for free
Start Your Free Trial100 free credits, no credit card required.

